Nowy HAL2, nowy CubeMX2, nowe IDE. ST odcina stary i nowy świat
W ostatnim artykule przyglądaliśmy się samej rodzinie STM32C5. Tam najważniejszy był hardware: nowy Cortex-M33 w low-costowej rodzinie, sensownie poukładane tiery pamięci, FDCAN praktycznie wszędzie i Ethernet w najwyższym wariancie. Ale już wtedy było widać, że C5 nie kończy się na samym mikrokontrolerze. Razem z tą rodziną ST wprowadza też nowy HAL2 i nowego CubeMX2, czyli tak naprawdę zaczyna większą zmianę w całym swoim ekosystemie.
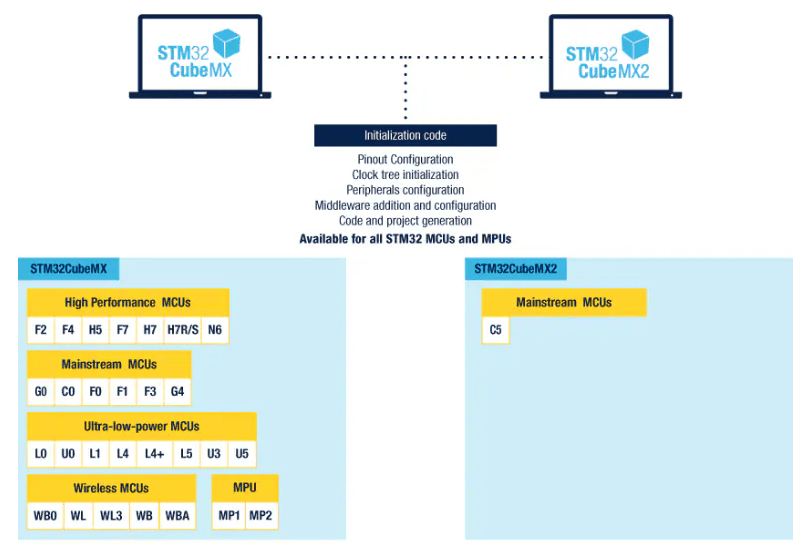
I tu właśnie zaczyna się ciekawsza część. Bo CubeMX2 i HAL2 na pierwszy rzut oka wyglądają jak zwykłe kolejne wersje narzędzi, które już dobrze znamy. Tylko że tutaj nie chodzi o numerki. ST nie wypuściło po prostu „nowego CubeMX-a”, tylko wyraźnie rozdzieliło swój świat na dwa tory. Na stronie STM32CubeMX widać to całkiem jasno: samo ST opisuje dziś to narzędzie jako rodzinę obejmującą STM32CubeMX i STM32CubeMX2. Czyli nie patrzymy na prosty update starego programu, tylko na początek nowego
I właśnie dlatego STM32C5 jest tu tak ważne. To nie jest tylko kolejna literka w portfolio ST, ale pierwsza rodzina po nowej stronie granicy. Stare układy zostają przy HAL1 i starym CubeMX-ie, a od C5 zaczyna się nowy tor: CubeMX2, HAL2 i cały nowy workflow wokół tego. Co ważne, ST podobnie komunikuje też IDE – obok klasycznego STM32CubeIDE pokazuje już STM32CubeIDE for VS Code jako drugi wariant środowiska. Czyli zmiana nie dotyczy jednego programu, tylko całego ekosystemu i sposobu pracy z nim.
Ten artykuł nie będzie jeszcze spacerem screen po screenie po nowym CubeMX2. To zrobimy osobno, bo szkoda to tutaj upychać na siłę. Tutaj chcę najpierw odpowiedzieć na ważniejsze pytanie: co ST właściwie zmienia, po co to robi i czy ten kierunek ma sens z perspektywy kogoś, kto naprawdę robi projekty na STM32. Bo jak wejdziesz głębiej, to szybko widać, że nie chodzi tylko o nowy wygląd narzędzia, ale o przebudowę całego toru pracy – od konfiguracji, przez generowanie projektu, aż po IDE.
Artykuł w formie wideo 👇
C5 jako granica między starym i nowym światem
W poprzednim tekście STM32C5 wyglądało przede wszystkim jak nowa, sensownie poukładana rodzina mikrokontrolerów. I to się oczywiście nie zmienia. Nadal mamy tu ciekawy hardware, nowy rdzeń i rodzinę, która ma ambicję być takim nowym „domyślnym wyborem” do wielu projektów. Ale im dłużej się temu przyglądam, tym bardziej widać, że samo C5 jest tu trochę pretekstem do czegoś większego. Bo tak naprawdę ST wykorzystało tę premierę jako moment, w którym można było przeciąć stary i nowy świat grubą kreską.
I to jest właśnie najważniejsze: STM32C5 nie jest tylko nową rodziną. To jest punkt graniczny całego ekosystemu. Stare rodziny zostają przy HAL1 i starym CubeMX-ie, a od C5 zaczyna się nowy tor: CubeMX2, HAL2 i reszta narzędzi dookoła. ST samo pokazuje dziś STM32CubeMX jako narzędzie obejmujące dwie wersje: STM32CubeMX i STM32CubeMX2. To nie wygląda jak klasyczne „wersja 6, wersja 7, wersja 8”, tylko bardziej jak świadome rozdzielenie dwóch ścieżek rozwoju.
Na papierze taki ruch może wyglądać trochę brutalnie. No bo naturalne pytanie brzmi: czemu nie zrobić jednego CubeMX-a, jednego HAL-a i po prostu rozwijać tego dalej? Tylko że właśnie tu zaczyna się ciekawa część. HAL1 przez lata urósł do dużego, trochę historycznego bytu, w którym nowe rzeczy trzeba było dopinać do starych założeń. Dało się z tym żyć, jasne. Ale było też coraz więcej tego bagażu, który trzeba było nosić dalej. I mam wrażenie, że ST w końcu uznało, że łatwiej będzie postawić wyraźną granicę niż udawać, że wszystko nadal da się elegancko zmieścić w jednym worku.
Z praktycznego punktu widzenia to ma nawet sens. Lepsze takie uczciwe cięcie niż sytuacja, w której przez kilka lat mamy trzy pół-kompatybilne warianty tego samego narzędzia, cztery poziomy zgodności wstecznej i jeszcze nie wiadomo, która rodzina jest już „nowa”, a która jeszcze „stara”. Tutaj zasada jest prosta: to, co wyszło wcześniej, zostaje po staremu. To, co wychodzi od C5 wzwyż, idzie już nową ścieżką. Nie ma mieszania i nie ma udawania, że wszystko będzie działać wszędzie tak samo.
To oczywiście nie znaczy, że cały temat jest od razu prostszy dla użytkownika. Wręcz przeciwnie – przez jakiś czas będziemy żyli w dwóch światach równocześnie. Raczej przez dłuższy czas. Jeden projekt na starszej rodzinie będzie siedział na HAL1 i starym CubeMX, a nowy projekt na C5 czy kolejnych rodzinach pójdzie już przez CubeMX2 i HAL2. Ale mimo wszystko wolę taki jasny podział niż niekończące się przejściówki. Przynajmniej wiadomo, gdzie kończy się stare, a gdzie zaczyna nowe.
Gdyby CubeMX2 był tylko odświeżonym interfejsem do starego generatora, to pewnie nie byłoby o czym pisać poza kilkoma screenami i listą nowości. Ale tutaj ST zmienia nie tylko jedno narzędzie. Ono przebudowuje cały tor pracy. CubeMX2 to jeden element, HAL2 to drugi, a do tego dochodzi jeszcze nowe IDE oparte o Visual Stusio Code. Sama strona STM32CubeIDE mówi już wprost, że są dwa warianty środowiska: klasyczne STM32CubeIDE i STM32CubeIDE for VS Code, a ST deklaruje, że mocniej koncentruje się teraz właśnie na wariancie opartym o VS Code. To dobrze pokazuje skalę tej zmiany.
CubeMX2 – nowy wygląd to najmniej ważna zmiana
Jak pierwszy raz odpalisz CubeMX2, to najbardziej rzuca się w oczy oczywiście interfejs. I to jest naturalne, bo po latach klikania w starego CubeMX-a człowiek od razu szuka wzrokiem tych samych miejsc, tych samych zakładek i tych samych przyzwyczajeń. Na pierwszy rzut oka nie widać, że tutaj nie chodzi o samo przemalowanie starego narzędzia. ST samo opisuje STM32CubeMX2 nie tylko jako konfigurator pinów i zegarów, ale również jako narzędzie do tworzenia projektów, zarządzania driverami, middleware, pakietami i podglądem kodu jeszcze przed generacją. W dokumentacji wprost przewijają się funkcje typu project creation, parts drivers management, pack management i code preview. To jest ważne, bo pokazuje, że CubeMX2 ma być czymś więcej niż tylko tym oknem, w którym klikasz UART-a i potem naciskasz „Generate”.
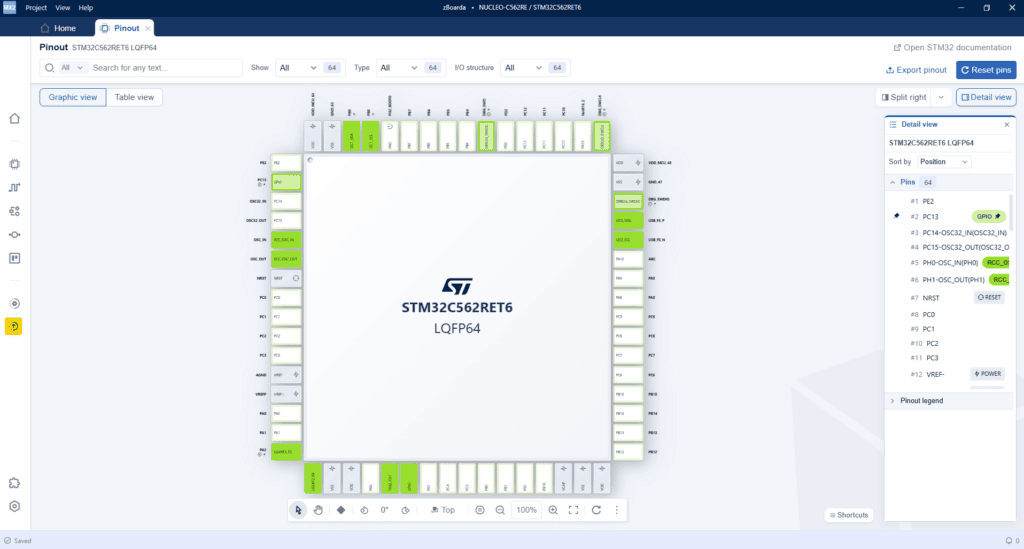
I tu właśnie jest myk: największa zmiana nie siedzi w kolorach, ikonkach ani układzie paneli. Najważniejsze jest to, jak ST chce, żeby tego narzędzia używać. W starym CubeMX-ie workflow był dość prosty i dość brutalny jednocześnie: konfigurujesz, generujesz projekt, wracasz, poprawiasz, generujesz jeszcze raz.
CubeMX2 zaczyna odklejać się od tego modelu. Mamy tutaj nowość w postaci code preview, która pokazuje, że ST próbuje przesunąć środek ciężkości z „wygeneruj cały projekt” na „zobacz najpierw, co to narzędzie właściwie chce ci zrobić z kodem”. Oficjalnie ST opisuje ten podgląd jako możliwość zobaczenia wygenerowanego kodu przed generacją projektu i kopiowania fragmentów kodu do własnego projektu. To już jest zmiana podejścia, a nie tylko nowa funkcja do odhaczenia w tabelce.
Na papierze wygląda to sensownie. Nawet bardzo sensownie. Bo jeżeli CubeMX2 naprawdę ma pozwalać podejrzeć efekt konfiguracji i wyciągnąć z niego tylko to, czego potrzebujesz, to jest to krok w stronę mniejszej magii i większej kontroli. Tylko że tu warto od razu trochę ostudzić entuzjazm. Bo pytanie brzmi: czy będzie to użyteczne? Za mną kilka spotkań na żywo z Wami i z nowym CubeMX2 i jeszcze z tego nie skorzystalismy.
Zresztą moje pierwsze wrażenia są dostępne na zapisie live’a. Widać sporo świeżych pomysłów i kilka rzeczy, które wyglądają nowocześniej niż wcześniej. Ale jednocześnie nie wszystko jest jeszcze intuicyjne z marszu. Są miejsca, gdzie trzeba się przestawić, są miejsca, gdzie nowy układ wymaga chwili oswojenia, i są też takie momenty, w których człowiek ma odruch: dobra, wygląda to ładniej, ale czy na pewno szybciej mi się tu pracuje? Przykładem może być zmuszanie nas do rozwijania wszystkich dostępnych opcji konfiguracji, zamiast ustawienia ich domyślnie jako rozwinięte. W starym CubeMX mieliśmy wszystko w formie tabeli – teraz rozwijane listy.
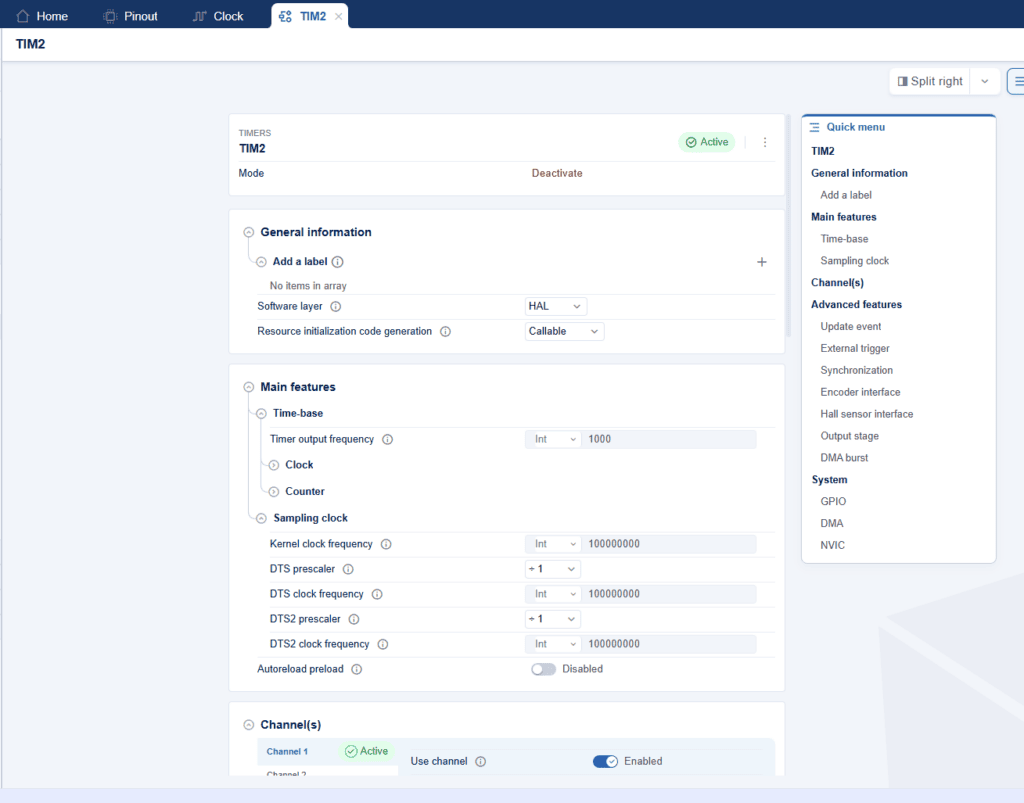
I właśnie dlatego nie chcę tu jeszcze robić spaceru screen po screenie. Na to będzie osobny materiał. Tutaj ważniejsze jest zauważenie jednej rzeczy: CubeMX2 nie wygląda jak odświeżony stary generator, tylko jak początek nowego modelu pracy z projektem.
CubeMX2 to też zmiana sposobu generowania projektu
Gdyby CubeMX2 kończył się tylko na nowym interfejsie i code preview, to i tak byłaby to jakaś zmiana. Ale tu dochodzi jeszcze jedna rzecz, dużo ważniejsza z punktu widzenia codziennej pracy: sposób generowania projektu. I tu już widać, że ST nie próbuje tylko odświeżyć stare narzędzie do generowania projektu, ale naprawdę przebudowuje workflow. W dokumentacji quick start dla CubeMX2 oraz w materiałach dotyczących STM32C5 przewija się wprost, że przy generowaniu projektu wybierasz format IDE, a dla nowych projektów na C5 bardzo wyraźnie pojawia się CMake jako docelowy format projektu. ST pokazuje go obok innych formatów, takich jak Open-CMSIS czy IAR, ale to właśnie CMake najmocniej wpisuje się w nowy tor pracy.
Oczywiście te rzeczu przebijały się w starym CubeMX w wersji Standalone, ale tutaj to wybrzmiewa jeszcze mocniej.
I to jest zmiana, której nie da się zbyć jednym zdaniem. Bo CMake sam w sobie nie jest żadną magią ani gwarancją szczęścia. Dalej można zrobić projekt, który będzie niby nowoczesny, a w praktyce upierdliwy. Ale sam fakt, że ST zaczyna generować projekty w ten sposób, jest bardzo czytelnym sygnałem. To znaczy, że przestają myśleć wyłącznie w kategoriach „wygeneruj katalog pod nasze konkretne IDE”, a zaczynają iść w stronę bardziej elastycznego modelu: konfiguracja osobno, build system osobno, edytor czy IDE osobno.
To się dobrze spina z całym nowym ekosystemem, bo jeśli CubeMX2 generuje projekt pod CMake, to dużo łatwiej potem połączyć to z różnymi środowiskami, automatyzacją albo CI. Zresztą ST samo publikuje już osobne materiały o integracji CMake z CubeMX i użyciu tego w STM32CubeIDE for VS Code, więc to nie wygląda na przypadkowy dodatek, tylko na kierunek, który realnie pchają do przodu.
Na papierze wygląda to dobrze. Nawet bardzo dobrze. Bo przez lata STM32-owy workflow był mocno związany z tym, co wygeneruje Cube i do jakiego IDE to potem wypchnie. Domyślnym środowiskiem pracy z STM32 było STM32CubeIDE oparte na Eclipse. Ja je lubię i nadal uważam, że do wielu rzeczy robi dobrą robotę. Ale jednocześnie nie ma co udawać, że to jest świeże podejście do developmentu. To jest narzędzie zbudowane wokół starszego modelu pracy: mocno zintegrowane, dość ciężkie i mniej elastyczne, kiedy chcesz je dobrze spiąć z nowoczesnymi toolami. I tu nie chodzi tylko o CI czy własny build system, ale też o rzeczy, które dziś po prostu wchodzą do codziennej pracy, jak choćby LLM-y wspomagające pisanie i analizę kodu. W takim świecie bardziej modularny workflow, z projektem generowanym pod CMake i środowiskiem opartym o VS Code, przestaje być fanaberią. To po prostu odpowiedź na to, jak dzisiaj naprawdę pracuje rynek.
I właśnie dlatego ruch ST ma sens. CubeMX2 przestaje być tylko generatorem projektu pod jedno konkretne środowisko, a zaczyna wpisywać się w bardziej elastyczny tor pracy. Dopiero praktyka pokaże, czy ST zrobiło to naprawdę wygodnie, ale sam kierunek jest po prostu potrzebny.
STM32CubeIDE for VS Code. ST wchodzi w Visual Studio Code
Jeżeli CubeMX2 i generowanie projektu pod CMake są jednym filarem tej zmiany, to drugim jest nowe IDE. I tu też nie ma co owijać w bawełnę: ST wyraźnie próbuje wyjść poza swój dotychczasowy, dość zamknięty model pracy. Na stronie STM32CubeIDE wprost widać dziś, że są dwa warianty środowiska. Pierwszy to klasyczne STM32CubeIDE oparte na Eclipse, obecne od 2019 roku i skierowane bardziej do osób, które lubią zintegrowane, GUI-owe środowisko skupione wokół debugowania. Drugi to STM32CubeIDE for VS Code, uruchomione w 2025 roku i kierowane do tych, którzy wolą lepszą edycję C/C++, integrację z Copilotem, większą elastyczność i bardziej płynne workflow CI/CD. I to już samo w sobie mówi bardzo dużo o tym, jak ST widzi przyszłość swojego toolchainu.
Co ważne, to nie wygląda jak próba zbudowania kolejnego ciężkiego IDE od zera, tylko raczej jak wejście w świat Visual Studio Code przez zestaw rozszerzeń, integracji i własnych narzędzi dookoła. Dokumentacja dla STM32CubeIDE for Visual Studio Code jest prowadzona osobno i obejmuje nie tylko instalację, ale też tworzenie pierwszego projektu, migrację między wersjami rozszerzeń, build, debug, integrację z zewnętrznymi toolami i całą resztę, która normalnie tworzy pełny workflow. To jest ważne, bo pokazuje, że ST nie traktuje tego jako dodatku obok, tylko jako pełnoprawną ścieżkę pracy. Co więcej, sama dokumentacja wprost opisuje projekty STM32CubeIDE for VS Code jako współpracujące z projektami generowanymi przez STM32CubeMX, z Makefile albo CMake, zależnie od ustawienia projektu.
I tu właśnie cała układanka zaczyna się dobrze spinać. CubeMX2 konfiguruje projekt. CMake staje się naturalnym formatem generacji. A STM32CubeIDE for VS Code daje środowisko, które dużo lepiej wpisuje się w to, jak dziś naprawdę pracują zespoły. Nie dlatego, że VS Code jest modne. Tylko dlatego, że taki model jest zwyczajnie bardziej elastyczny. Łatwiej go połączyć z własnym repo, z CI, z innymi rozszerzeniami, z narzędziami do analizy kodu i — co dziś też ma znaczenie — z LLM-ami wspomagającymi development. ST samo to zresztą komunikuje, wskazując właśnie na Copilota, elastyczność i CI/CD jako argumenty za wariantem VS Code.
No i tu mogę uczciwie powiedzieć jedną rzecz: ja sam nie jestem jeszcze mistrzem VS Code. Znam go, używałem, ale nie jestem kimś, kto od lat siedzi w tym środowisku od rana do nocy. Więc będziemy się tego trochę uczyć razem. I moim zdaniem to nawet dobrze. Bo zamiast udawać, że cały ten nowy workflow mam już rozpracowany na wylot, lepiej potraktować to tak, jak traktuje to pewnie sporo osób pracujących dziś na STM32: klasyczne CubeIDE jest znajome i wygodne, ale widać już, że świat idzie w stronę bardziej modularnych, bardziej elastycznych narzędzi. A ST po prostu zaczyna za tym nadążać.
To nie znaczy oczywiście, że wszystko jest już idealne. Samo ST dziękuje społeczności za cierpliwość i feedback, pisząc wprost, że zespół nadal rozwija narzędzia dla VS Code. W community przewijają się też informacje o brakujących jeszcze bardziej zaawansowanych ficzerach debugowych czy o rzeczach, które są nadal dopracowywane. Czyli znowu: kierunek wygląda dobrze, ale cały ten tor pracy jest jeszcze świeży i cały czas dojrzewa. I właśnie dlatego nie chcę go tu jeszcze opisywać jak czegoś w pełni domkniętego. Bardziej jako bardzo ważną zmianę, którą po prostu warto już teraz obserwować i testować.
HAL2 – zmiana filozofii
Przy CubeMX2 i nowym IDE łatwo się skupić na narzędziach, bo to widać od razu. Ale tak naprawdę najciekawsza zmiana siedzi głębiej, w samym HAL-u. I tu bardzo łatwo się pomylić, bo na slajdach czy w skrótowych opisach HAL2 może wyglądać jak „HAL, tylko trochę lżejszy, trochę szybszy i trochę bardziej nowoczesny”. No właśnie, nie do końca. Im bardziej zaglądam w dokumentację migracyjną ST, tym wyraźniej widać, że oni sami nie traktują tego jako zwykłego liftingu. W przewodniku HAL1 → HAL2 jest osobna sekcja zatytułowana Breaking changes in concepts. Sam ten nagłówek mówi już bardzo dużo. To nie jest komunikat w stylu „pozmienialiśmy parę nazw funkcji”. To jest wprost przyznanie, że zmieniają się pewne podstawowe założenia tej biblioteki.
I to zresztą widać po liście tematów, które ST tam rozpisuje. Nie są to jakieś drobne poprawki, tylko zmiany w samych założeniach biblioteki, między innymi:
- zoptymalizowane API inicjalizacji i konfiguracji,
- metody konfiguracji atomowej,
- bardziej wyspecjalizowane zarządzanie zegarami i przerwaniami,
- HAL2 zbudowany na bibliotece LL,
- HAL2 świadomy pracy z RTOS-em,
- nowe reguły pisania kodu,
- ogólny refaktoring biblioteki.
i jeszcze kilka innych rzeczy. Czyli nie tylko API, ale cały sposób myślenia o tym, jak HAL1 ma być zbudowany i jak ma się go używać. ST samo pokazuje to jako zmianę koncepcyjną, a nie kosmetyczną. To jest dla mnie ważne, bo potwierdza coś, co było czuć już wcześniej: pierwszy HAL przez lata zwyczajnie obrósł w różne historyczne decyzje, kompromisy i wzorce, które dało się utrzymywać, ale niekoniecznie dało się już dalej rozwijać bez coraz większego bałaganu. HAL2 wygląda więc bardziej jak próba uporządkowania tego od środka niż tylko odchudzenia paru driverów.
I tu właśnie ten nowy HAL2 robi się naprawdę ciekawy. Bo ST nie tylko mówi o optymalizacjach, ale próbuje też uprościć strukturę biblioteki, ujednolicić pewne mechanizmy i mocniej oprzeć wszystko na bardziej spójnym fundamencie. W dokumentacji wprost pojawia się informacja, że HAL2 jest budowany na usługach LL. Do tego dochodzą zmiany w regułach kodowania, refaktoryzacja wspólnego include’a
1 | stm32_hal.h |
I szczerze mówiąc, to jest dla mnie najważniejszy sygnał z całego HAL2. Nie to, że gdzieś tam spadło zużycie flasha o jakiś procent, tylko to, że ST w końcu wygląda, jakby chciało ten HAL posprzątać naprawdę, a nie tylko dopisać kolejną warstwę na istniejącym bałaganie. Czy to się uda? To jest osobne pytanie. Ale sam kierunek wygląda sensownie. I dobrze też, że ST nie próbuje udawać, że nic wielkiego się nie zmienia, tylko samo daje narzędzia migracyjne i dokumentację, która wprost mówi: tak, tu są breaking changes i trzeba je potraktować poważnie.
Samo API w HAL 2 też się zmieniło
Jak zaczęliśmy się tym HAL2 bawić na live’ach, to dość szybko wyszło, że to API jest jednocześnie znajome i trochę inne. I to jest chyba najlepsze podsumowanie pierwszego kontaktu. Nie ma tu rewolucji pod tytułem „uczymy się wszystkiego od zera”, bo nazewnictwo i ogólny styl są nadal STM-owe i dobrze nam znane. Ale też nie jest to stary HAL przebrany w nowe ubranie. Już przy najprostszych testach z UART-em było widać, że kilka rzeczy działa inaczej, kilka jest bardziej rozbudowanych, a kilka wymaga po prostu przestawienia myślenia.
Największa zmiana dla mnie? Pozbyli się
1 | extern |
1 | huart2 |
1 | htim3 |
1 | extern |
1 | <em>mx_usart2_uart_gethandle()</em> |
Zmiany widać też na naszych wspólnych testach na żywo z UARTem. Z jednej strony podstawowe funkcje wyglądają znajomo. Nadal mamy zwykłe transmitowanie, warianty przerwaniowe, callbacki i cały ten znany świat. Z drugiej strony API jest wyraźnie bogatsze niż wcześniej. W oficjalnej dokumentacji HAL2 UART dla STM32C5 ST pokazuje nie tylko klasyczne scenariusze TX/RX, ale też odbiór do idle, do timeoutu i do konkretnego znaku — i to zarówno w polling, jak i w wariantach IT oraz DMA. Czyli tam, gdzie wcześniej często trzeba było coś sobie dopisać albo składać z kilku mechanizmów, tutaj dostajemy bardziej gotowe use case’y. I akurat to wygląda sensownie.
Na live’ach było też dobrze widać, że callbacki robią się bardziej szczegółowe. To już nie jest taki prosty model, że „coś się skończyło i dostajesz tylko uchwyt”. W części callbacków pojawia się dodatkowa informacja, na przykład rozmiar transferu albo typ zdarzenia. I to jest akurat zmiana na plus, bo mniej rzeczy trzeba sobie potem zgadywać albo odtwarzać bokiem z kontekstu.
Była też jeszcze jedna rzecz, która bardzo mi się spodobała i którą warto podkreślić. W HAL2 funkcje związane z DMA nie są już „wszędzie na wszelki wypadek”. Jak nie włączysz DMA dla danego kierunku, to odpowiednie kawałki API po prostu się nie pojawiają w wygenerowanym projekcie. I moim zdaniem to jest zmiana na plus. W poprzednim HAL-u część funkcji DMA była obecna praktycznie zawsze, nawet jeśli w projekcie DMA nie było realnie skonfigurowane. To mogło być mylące, bo człowiek widział funkcję, używał jej, a dopiero później wychodziło, że pod spodem i tak nie ma do czego tego podłączyć. Tutaj to zachowanie wygląda bardziej uczciwie: nie skonfigurowałeś DMA, to nie dostajesz API, które sugeruje, że DMA jest gotowe do użycia. To jest drobiazg, ale bardzo dobrze pokazuje, że HAL2 i CubeMX2 próbują mocniej spiąć wygenerowany kod z realną konfiguracją projektu, zamiast zostawiać użytkownika z półprawdami.
Czyli moje pierwsze wrażenie z samego API jest takie: HAL2 jest podobny do HAL, ale bardziej rozbudowany i bardziej świadomy konkretnego use case’u. W paru miejscach wygląda sensowniej niż wcześniej. W paru wymaga przyzwyczajenia. Ale najważniejsze jest to, że widać tu zmianę podejścia, a nie tylko zmianę numerka w nazwie biblioteki.
HAL2 i LL. Zaczyna to wyglądać spójnie
Jedna z ważniejszych zmian w HAL2 to dużo mocniejsze spięcie z warstwą LL. W starym ekosystemie LL oczywiście istniał, ale często wyglądało to tak, jakby HAL i LL żyły trochę obok siebie. Tutaj ST samo komunikuje to już dużo wyraźniej. W dokumentacji migracyjnej jednym z głównych punktów zmian koncepcyjnych jest wprost implementacja HAL2 oparta o bibliotekę LL. Czyli nie chodzi o przypadkowe użycie kilku funkcji niskiego poziomu, tylko o bardziej świadomą architekturę całej warstwy abstrakcji.
I to akurat wygląda sensownie. Jeżeli HAL ma być lżejszy, bardziej przewidywalny i mniej historyczny niż wcześniej, to bez takiego mocniejszego związku z LL raczej by się nie udało. Dzięki temu HAL2 przestaje wyglądać jak osobny, ciężki byt, a bardziej jak sensowna nakładka na niższą warstwę. Z praktycznego punktu widzenia to może oznaczać mniej duplikacji, łatwiejsze schodzenie poziom niżej tam, gdzie naprawdę jest to potrzebne, i bardziej spójny kod w całym ekosystemie. Na papierze to jest jedna z tych zmian, które nie robią takiego wrażenia jak nowe IDE czy nowy wygląd CubeMX2, ale architektonicznie mogą znaczyć dużo więcej.
Gdzie tu są realne plusy?
Najłatwiej byłoby teraz powtórzyć slajdy ST o mniejszym footprintcie, lepszej architekturze i nowym workflow, bla bla bla. Tylko że z punktu widzenia człowieka, który naprawdę siedzi w projektach, ważniejsze są trochę inne rzeczy. Dla mnie największy plus tego nowego stacku jest taki, że on w końcu zaczyna wyglądać spójnie.
CubeMX2 nie jest już tylko klikalnym generatorem (choć liczba klików na sekundę zwiększyła się przez rozwijane listy). Projekty idą w stronę CMake, do tego dochodzi STM32CubeIDE for VS Code, a HAL2 próbuje uporządkować warstwę abstrakcji od środka.
To nie są trzy przypadkowe nowości wrzucone do jednego worka, tylko elementy jednego kierunku. ST samo komunikuje dziś CubeMX jako rodzinę obejmującą STM32CubeMX i STM32CubeMX2, a CubeIDE jako środowisko dostępne także w wariancie for VS Code. To dobrze pokazuje, że zmiana nie dotyczy jednego programu, tylko całego toru pracy.
Drugi realny plus jest bardziej przyziemny: mniej legacy, więcej jawności. Widać to i w API, i w organizacji projektu. Koniec z częścią starych przyzwyczajeń typu bezrefleksyjne
1 | externy |
I to akurat odbieram pozytywnie, bo to znaczy, że nie próbują pudrować starego HAL-a, tylko faktycznie go przebudowali. Oczywiście dopiero praktyka pokaże, ile z tego wyjdzie naprawdę dobrze. Ale sam kierunek wygląda jak coś, czego ten ekosystem po prostu już potrzebował.
Migracja HAL1 → HAL2? Jest, ale…
Warto wiedzieć, że ST przygotowało już migration guide z HAL1 do HAL2 i do tego dorzuciło HAL2 Migrator. W momencie pisania tego artykułu praktyczna dokumentacja używania samego narzędzia jest po prostu słaba. Wręcz jej brakuje.
Jest dużo materiału o różnicach, koncepcjach i mapowaniu API, ale nadal brakuje czegoś, co pozwalałoby powiedzieć: dobra, to jest dopracowany, sprawdzony workflow, który można spokojnie powtórzyć krok po kroku.
Nawet polski oddział ST przyznaje, że sami jeszcze szerzej się tym nie bawili, bo nie bardzo wiadomo, jak do tego sensownie podejść w praktyce. Więc na dziś potraktowałbym to bardziej jako zapowiedź kierunku, a nie narzędzie, które można już polecać w ciemno.
I jeszcze ważne doprecyzowanie: nie chodzi o to, że starsze rodziny STM32 będą nagle migrowane na HAL2. Granica dalej jest twarda. Stare rodziny zostają przy starym stacku, a nowe wchodzą w nowy. Ten migration guide trzeba rozumieć raczej tak: jeżeli masz projekt napisany na HAL1 i chcesz go przenieść na nową rodzinę działającą już na HAL2, to ST daje ci do tego pewne materiały i narzędzia. To ma sens, tylko na razie trzeba jeszcze poczekać, aż ten temat bardziej dojrzeje – zarówno po stronie dokumentacji, jak i realnych doświadczeń ludzi, którzy będą to robić na żywych projektach.
Podsumowanie
Na pierwszy rzut oka można by to wszystko sprowadzić do prostego hasła: nowy HAL, nowy CubeMX, nowe IDE. Tylko że po przejrzeniu tego bliżej widać, że tutaj nie chodzi o trzy osobne nowości. ST po prostu przebudowuje cały swój tor pracy wokół nowych rodzin, a STM32C5 jest pierwszym miejscem, w którym to widać tak wyraźnie. Z jednej strony mamy twardą granicę między starym i nowym światem. Z drugiej – nowy CubeMX2, projekty generowane pod CMake, nowe IDE oparte o VS Code i HAL2, który wygląda jak próba posprzątania rzeczy, które przez lata narosły w HAL1. ST zresztą samo komunikuje dziś CubeMX jako rodzinę obejmującą STM32CubeMX i STM32CubeMX2, a CubeIDE jako środowisko dostępne także w wariancie STM32CubeIDE for VS Code.
I moim zdaniem to jest zmiana na plus. Nie dlatego, że wszystko jest już gotowe, dopracowane i bezbłędne. Bo nie jest. Tylko dlatego, że ten ekosystem po prostu potrzebował nowego otwarcia. Rynek od dawna poszedł w stronę bardziej elastycznych workflow, lepszej integracji z nowoczesnymi narzędziami i większej jawności w kodzie. Stary stack ST dawał się używać, ale coraz bardziej było czuć, że ciągnie za sobą sporo historycznego bagażu. HAL2, CubeMX2 i nowy tor oparty o CMake oraz VS Code wyglądają jak sensowna odpowiedź na ten problem.
Na dziś najuczciwiej byłoby powiedzieć tak: kierunek wygląda dobrze, ale to nadal początek drogi. W kilku miejscach widać bardzo sensowne decyzje. W kilku innych widać jeszcze świeżość i niedojrzałość. Do tego dochodzi temat migracji HAL1 → HAL2, który formalnie już istnieje, ale praktycznie nadal bardziej zapowiada przyszły workflow niż daje gotowe, dopracowane narzędzie do użycia od ręki. Nawet sama dokumentacja migracyjna pokazuje, że zmian jest dużo i że ST traktuje to jako realne breaking changes in concepts, a nie prosty lifting.
Więc mój wniosek jest taki: warto się tym interesować już teraz, bo właśnie tędy będzie szło ST w kolejnych rodzinach. Ale jednocześnie nie ma sensu udawać, że wszystko jest już zamknięte i poukładane. To jest moment, w którym najlepiej po prostu wejść, popatrzeć, potestować i wyrobić sobie własne zdanie. A w kolejnym artykule zrobimy już bardziej techniczne przejście po samym CubeMX2 i jego UX, bo tam też jest o czym pogadać.
Jeśli chcesz poznawać ze mną nowego HAL2, to zapraszam Cię na moje Live’y na moim kanale YouTube: https://www.youtube.com/@msalamon
Oj, ale długi artykuł mi wyszedł… obiecuję, że już w kolejnych będę bardziej konkretny w techniczne szczegóły. W następnym wpisie przyjrzymy się z bliska nowemu CubeMX2 👌
Podobne artykuły







0 komentarzy