Nieuchronnie zbliża się ten czas, gdy z telewizora będzie wyjeżdzała nam czerwona ciężarówka, a na każdym kroku będziemy słyszeć piękną piosenkę o złamanym sercu, którą społeczność uznaje za kreacje swiątecznego klimatu. Tak, niedługo Boże narodzenie i oczywiście nie ma świąt bez światełek! Każdy elektronik już kilka miesięcy wcześniej głowi się jak by tu zaskoczyć sąsiada. Zwykłe diody RGB niestety już dawno stały się powszechne, ale pomocą przychodzą diody tzw. “adresowalne” WS2812B które od kilku lat królują jeśli chodzi o efekty świetlne.
Ten artykuł jest częścią cyklu:7

Czym są diody WS2812B?
Są to diody RGB w obudowie 5050 z wbudowanym kontrolerem PWM o rozdzielczości 8-bit na każdy kolor. Wartości wypełnienia PWM dostarczane są w postaci cyfrowej poprzez tylko jedną linię danych. Z diodami WS2812B rozmawiamy za pomocą jednoprzewodowej komunikacji NZR podobnie jak 1-Wire przy czym komunikacja w przypadku diod jest jednokierunkowa. Oznacza to, że możemy wysłać do diody informacje o tym jak ma się ustawić, ale nie dowiemy się od niej w jakim znajduje się stanie. Na szczęście nie jest to jakiś szczególny problem. Jak to wygląda? Oczywiście najlepiej wszystko tłumaczy dokumentacja diod ( WS2812B Datasheet ). Mimo że jest ona bardzo krótka to skrócę tutaj najważniejsze informacje.
Przesyłane sygnały podobnie tak jak w przypadku 1-Wire mają z góry określone stałe czasowe. Do pełni szczęścia potrzebne nam są jedynie 3 sygnały: logiczne 0, logiczne 1 oraz RESET.
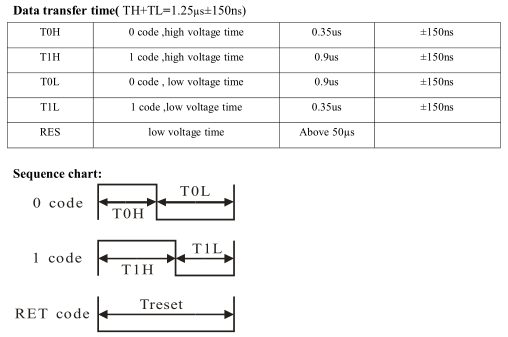
Z powyższego obrazu wynika, że częstotliwość komunikacji znajduje się w okolicach 800 kHz.
Ważnym feature’m diod jest możliwość łączenia ich kaskadowo. Diody posiadają 4 nóżki. Dwie oczywiście do zasilania (w zakresie 3,5÷5,3 V) oraz dwie dla danych – wejście i wyjście. Dioda po dostarczeniu niej wszystkich potrzebnych jej bajtów na temat kolorów, automatycznie przerzuca sygnał wejściowy na swoje wyjście. Dzięki temu można łączyć je teoretycznie w nieskończone łańcuchy. 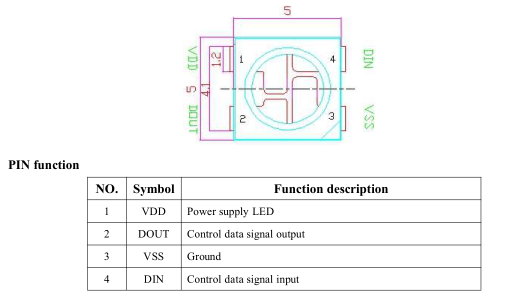
Producent zaznacza również, aby przy każdej diodzie w kaskadzie zajdował się kondensator 100 nF. Dostępne w zakupie taśmy z Państwa Środka posiadają takie kondensatory.
Sekwencja wpisywania danych do diod rozpoczyna się od sygnału RESET trwającego co najmniej 50 µs. Następnie idą dane dla diod w kolejności GRB od pierwszej do ostatniej diody. Ważne jest to, że dane nie mogą mieć absolutnie żadnej przerwy podczas przesyłania. Od momentu w którym wystąpi anomalia kolory zaczną być inne niż planowane.
Kod STM32
Dzisiaj będę bazował na STM32F103C8T6 który znajduje się w tanich płytkach z Chin szerzej znanych jako BluePill. Te chińskie moduły są bardzo popularne i tanie. Sam mam ich kilka, więc czemu by ich nie używać.

Mikrokontrolery nie mają sprzętowej obsługi interfejsu wymaganego przez diody WS2812B. Trzeba poradzić sobie w inny sposób. Pierwsze do głowy przychodzi banglowanie GPIO. W AVR programiści radzą sobie poprzez asemblerową instrukcję ‘nop’ dzięki której można w mniej lub bardziej kontrolowany sposób odczekać wymagany czas do zmiany stanu. Leczy używając nopów w STM32 nie sprawię, że napiszę uniwersalną i przenośną bibliotekę – mamy mnóstwo różnych konfiguracji MCU i używamy mnóstwo różnych taktowań. Potrzebuję czegoś lepszego. Można pilnować GPIO Timerem i zmieniać jego stan po określonych czasach. Może zdałoby to egzamin, ale nie próbowałem nawet tego sposobu. Natknąłem się w internecie na pomysł użycia sygnału MOSI z interfejsu SPI. Wydało mi się to ciekawe więc zacząłem drążyć temat. Schemat połączenia paska diod jest banalnie prosty. Wykorzystam SPI numer 1. Uwaga! Nie zasilaj bezpośrednio z modułu STM32. Diody WS2812B potrzebują przy maksymalnych jasnościach ~50 mA prądu na każdą sztukę. Łańcuch 60 diod/metr będzie w takim wypadku wymagał ~3 A/metr przy pełnym, jasnym białym świetle! Zasilanie dostarczaj z zewnątrznego wydajnego zasilacza.
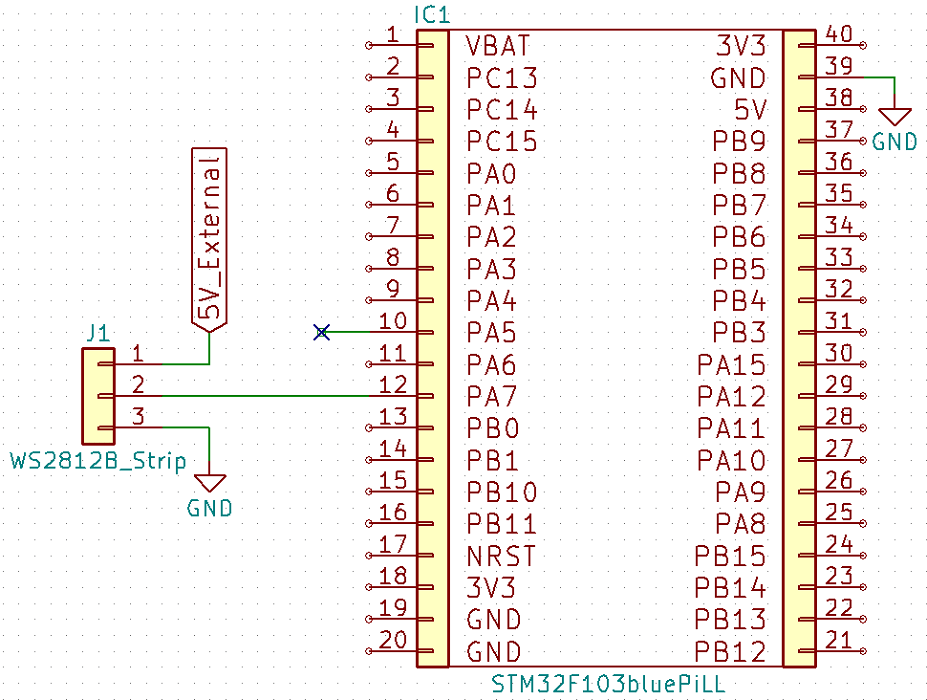
Pin PA5 służy jako SCK interfejsu SPI1. Nie będzie on potrzebny lecz w tym wypadku nie można go użyć do inego celu niż SPI.
Aby kontrolować szerokość impulsu sygnału NRZ musiałem wykorzystać cały bajt SPI jako jeden bit dla diody. Także czas trwania jednego bajtu powinien wynosić ok 1,25 µs więc jeden bit SPI powinien trwać ok 0,156 µs. Daje to taktowanie SPI na poziomie 6,4 MHz. W F103C8T6 wartość prescalera SPI do wyboru mam 2, 4, 8, 16, 32, 64, 128 i 256 co odpowiednio daje taktowanie MCU:
- 2 * 6,4 = 12,8 MHz
- 4 * 6,4 = 25,6 MHz
- 8 * 6,4 = 51,2 MHz
- 16 * 6,4 = 102,4 MHz…

Wartości szczerze mówiąc nieciekawe. Ciężko jest ustawić takie w Cube. Spotkałem się na pewnym popularnym forum ze stwierdzeniem, że MUSI BYĆ 6,4 MHz I KROPKA! No niestety, ale nie musi. Na mamy coś takiego jak tolerancja(w końcu tyle się o nią wszędzie walczy) i dla WS2812B tolerancja sygnałów wejściowych może być w wysokości ±0,15 µs, czyli ±0,66 MHz. Dużo łatwiej będzie uzyskać 6 MHz na SPI np za pomocą 48 MHz taktowania MCU i prescalera SPI ustawinego na wartość 8. Cube dodatkowo podpowiada baudrate SPI po wybraniu prescalera. Jeśli chcesz wyższego/niższego takowania MCU, szukaj takiego, na którym prescaler da ~6 MHz na SPI.

6 MHz oznacza czasy trwania bitów:
- 1 bit – 0,166 µs
- 2 bit – 0,333 µs
- 3 bit – 0,499 µs
- 4 bit – 0,666 µs
- 5 bit – 0,833 µs
- 6 bit – 0,999 µs
- 7 bit – 1,166 µs
- 8 bit – 1,333 µs
Czy coś z powyższych czasów pasuje do tabelki stałyczh czasowych WS2812B?
Do T0H podpasują 2 bity (0,35 µs ±0,15) a do T1H 5 bitów (0,9 µs ±0,15). Reszta naturalnie też podpasuje 😉
Jako, że SPI transferowane jest od MSB(dzięki Piotr!), definicje stanów logicznych wyglądać będą następująco:
#define zero 0b11000000 #define one 0b11111000
Dla ułatwienia powołałem strukturę która zawiera dane dla kolorów jednej diody.
typedef struct ws2812b_color {
uint8_t red, green, blue;
} ws2812b_color;
Podstawowa biblioteka zawiera tylko trzy samokomentujące się funkcje.
void WS2812B_Init(SPI_HandleTypeDef * spi_handler); void WS2812B_SetDiodeColor(int16_t diode_id, ws2812b_color color); void WS2812B_Refresh();
Inizjalizacja polega jedynie na przypisaniu wskaźnika na SPI do biblitoteki.
Ustawienie diody dokonuje się przez numer diody w kaskadzie oraz podanie zmiennej strukturalnej z kolorami tej diody.
Odświeżenie ustawia bajty bufora SPI według kolorów diod. Tworzony jest w niej wielki bufor, który zawiera wszystkie dane dla wszystkich diod. Niestety zjada to ogromne ilości RAMu, ale jest na to rada o czym będzie za chwilę.
Przesłanie danych
Myślę, że przesyłanie danych do diod jest warte omówienia. Jest to bowiem ciekawe wyzwanie, aby dane dotarły do diod jednym ciągiem oraz niewielkim nakładem MCU.
Przygotowanie danych w buforze według kolorów zawiera sporo przesunięć bitowych które na szczęście są lekkie dla MCU.
for(uint8_t i = 0; i < 72; i++)
buffer[i] = 0x00;
for(uint16_t i=0, j=72; i<WS2812B_LEDS; i++)
{
//GREEN
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[i].green & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//RED
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[i].red & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//BLUE
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[i].blue & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
}
HAL_SPI_Transmit(hspi_ws2812b, buffer, (WS2812B_LEDS+3) * 24, 1000);
I to działa, ale nie do końca poprawnie. Niestety końcowe najczęściej 3-4 diody przy pasku 100 sztuk mają losowe kolory. Bierze się to pewnie stąd, że podczas transferu SPI wpada jakieś przerwanie. Prawdopodobnie jest to przerwanie SysTick Timera, ale nie sprawdzałem – nie ma sensu. Można je wyłączyć, ale nie polecam. Co teraz? Każdy STM32 ma coś takiego jak DMA. Tłumacząc na polski jest to takie peryferium o bezpośrednim dostępie do pamięci. Można mu oddelegować jakąś operację związaną z pamięcią lub innym peryferium. Dzięki temu MCU ma czas na wykonywanie innych zadań jak np. przerwanie SysTick które burzyło transfer danych do diod.
Konfiguracja DMA w Cube jest prosta. W zakładce Configuration i tabeli System jest przycisk konfiguracji DMA. Dodaj konfiguracje DMA dla SPI1_TX, które zostało wcześniej skonfigurowane. Priorytet ustaw jako Very High ponieważ jest to kluczowa operacja. W ustawieniach w dolnej części tryb Normal oraz inkrementację danych dla pamięci, w tym wypadku będzie to bufor RAM.
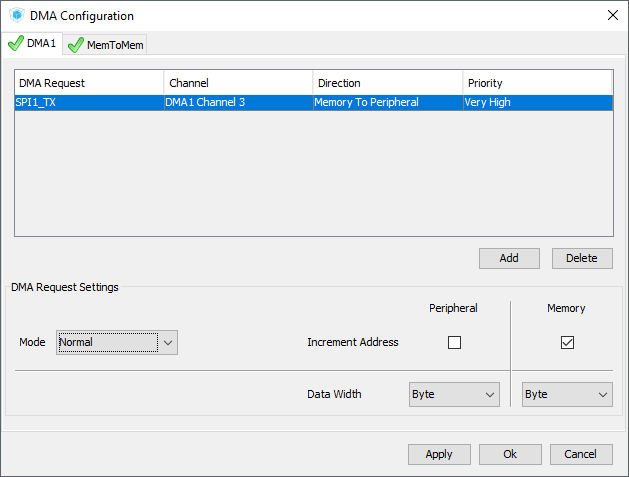
Jak teraz ma działać? Zmienia się tylko wywołanie transferu danych po SPI w funkcji odświeżąjącej. Teraz wygłąda to tak:
HAL_SPI_Transmit_DMA(hspi_ws2812b, buffer, (WS2812B_LEDS+3) * 24); while(HAL_DMA_STATE_READY != HAL_DMA_GetState(hspi_ws2812b->hdmatx));
Druga linijka jest to oczekiwanie na zakończenie transferu. Można z niej zrezygnować, ale należy robić to świadomie i uważać na to, aby nie spowodować “kolizji” na DMA bo się wszystko popsuje.
![]()
Teraz diody działają miodzio. Każda ma dokładnie ten kolor który przewidziałem.
Przesłanie danych dla 35 diod(tyle mam podłączone do testów) to nieco ponad 1 ms, a dokładniej 1,22 ms. Czas potrzebny na przygotowanie bufora do wysłania to 0,27 ms z życia MCU. Do prostych zastosowań można czas transferu odczekać tak jak to zrobiłem. Warto jednak pokusić się o wykorzystanie tego czasu na inne zadania. Jest to prawie milisekunda przy zaledwie 35 diodach. Sterując ilością 100 diod ten zaoszczędzony czas będzie wynosił około 2,8 ms, a tysiąc diod to już 28 ms. Oszczędność spora bo można w tym czasie odświeżyć jakiś TFT zamiast bezczynnie czekać.
Niestety ogromną wadą tego rozwiązania jest bufor danych przekazywany do transferu SPI. Każda dioda pożera 24 bajty z RAMu. Dla STM32F103C8T6 kompilator zgłasza problemy z pamięcią już przy około 300 diodach. Trochę smutno 🙁
Ograniczenie zużycia RAM
Jest na to sposób! Każdy STM32 nie dość, że ma DMA to jeszcze kilka ciekawych przerwań które może ono wywołać w trakcie swojej pracy.
- Half-transfer
- Transfer complete
- Transfer Error
Pierwsze dwa będą idealne. Przecież można stworzyć mały bufor danych, puścić cykliczne DMA i w momencie wystąpienia przerwania od połowy wykonanego transferu, podmienić pierwszą połowę bufora. Genialne! Zauważ też , że przygotowanie kompletnego bufora trwa zdecydowanie mniej czasu niż przesłanie połowy tego bufora. MCU powinien zdążyć z palcem w… GND 😉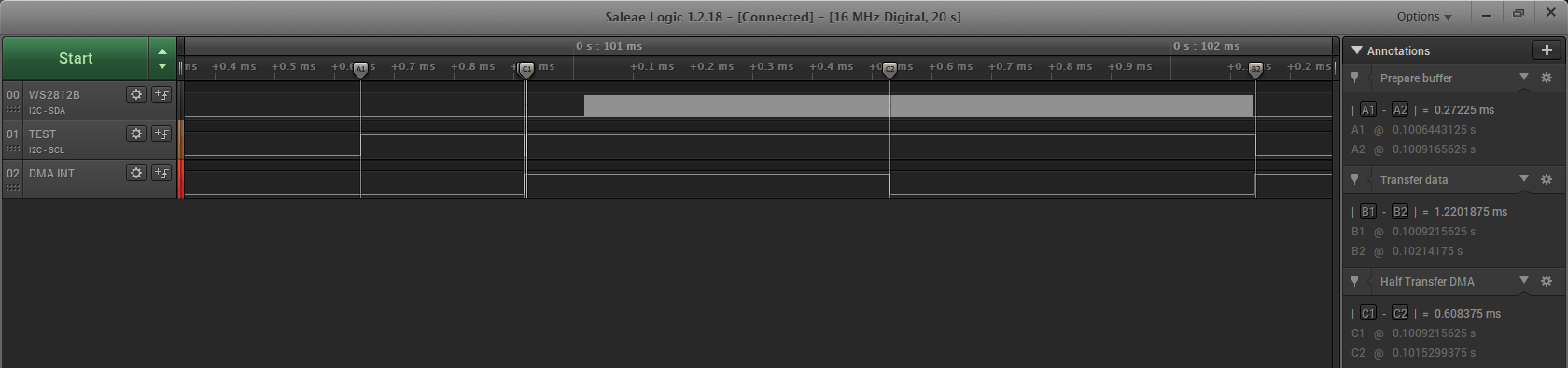
Ważna rzecz: Funkcja startująca transfer SPI przez DMA przyjmuje rozmiar bufora trzymającego dane, a nie ilości wszystkich danych które chcesz przesłać! Wystartowanie DMA w trybie bufora cyklicznego będzie wysyłało dane dopóki tego ręcznie nie przerwiesz. Dlatego w przerwaniach half-transfer i full-transfer trzeba liczyć dla ilu diod już wysłano danych i po ostatniej paczce zatrzymać DMA.
Bufor danych skrócę do 48 bajtów, czyli zmieszczą się w nim dane dla dwóch diod. Ładnie będzie się to paczkowało. Schemat działania jest następujący:
- Załaduj 2*24 bajty sygnału reset i wystartuj cykliczną transmisję DMA.
- Half-transfered trigger – załaduj kolejne 24 bajty do pierwszej połowy bufora.
- Full-transfered trigger – dane pierwszej diody do drugiej połowy bufora
- Half-transfered trigger – dane drugiej(parzystej) diody do pierwszej połowy bufora
- Full-transfered trigger – dane trzeciej(nieparzystej) diody do drugiej połowy bufora
- Powtarzaj 4 i 5 aż wszystkie diody zostaną przesłane
- Ciesz się efektem
Ciekawostka. Biblioteka HAL jest napisana w taki sposób, że callbacki poszczególnych przerwań DMA są w niej zadeklarowane z symbolem weak. Oznacza to, że można je nadpisać w swoich plikach źródłowych jednak muszą mieć tą samą nazwę, argumenty oraz zwracany typ. ST napisało HALa tak, aby nie martwić się o włączanie odpowiednich przerwań DMA za pomocą bitów i rejestrów. Jeżeli zadeklarujemy własne funkcje adekwatne do wymaganego przez nas przerwania, wewnątrz funckji HAL_SPI_Transmit_DM zostanie wykryty ten fakt i biblioteka sama za nas aktywuje odpowiednie przerwania. Nie trzeba się o nic martwić. Fajnie, nie? Jedyne o czym należy pamiętać to aktywowanie w Cube globalnego przerwania od DMA i nadanie mu priorytetu. Przechodząc do mojego kodu:
void WS2812B_Refresh()
{
CurrentLed = 0;
ResetSignal = 0;
for(uint8_t i = 0; i < 48; i++)
buffer[i] = 0x00;
HAL_SPI_Transmit_DMA(hspi_ws2812b, buffer, 48); // Additional 3 for reset signal
while(HAL_DMA_STATE_READY != HAL_DMA_GetState(hspi_ws2812b->hdmatx));
}
void HAL_SPI_TxHalfCpltCallback(SPI_HandleTypeDef *hspi)
{
if(hspi == hspi_ws2812b)
{
if(!ResetSignal)
{
for(uint8_t k = 0; k < 24; k++) // To 72 impulses of reset
{
buffer[k] = 0x00;
}
ResetSignal = 1; // End reset signal
}
else // LEDs Odd 1,3,5,7...
{
if(CurrentLed > WS2812B_LEDS)
{
HAL_SPI_DMAStop(hspi_ws2812b);
}
else
{
uint8_t j = 0;
//GREEN
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].green & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//RED
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].red & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//BLUE
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].blue & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
CurrentLed++;
}
}
}
}
void HAL_SPI_TxCpltCallback(SPI_HandleTypeDef *hspi)
{
if(hspi == hspi_ws2812b)
{
if(CurrentLed > WS2812B_LEDS)
{
HAL_SPI_DMAStop(hspi_ws2812b);
}
else
{
// Even LEDs 0,2,0
uint8_t j = 24;
//GREEN
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].green & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//RED
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].red & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
//BLUE
for(int8_t k=7; k>=0; k--)
{
if((ws2812b_array[CurrentLed].blue & (1<<k)) == 0)
buffer[j] = zero;
else
buffer[j] = one;
j++;
}
CurrentLed++;
}
}
}
Wyniki zmniejszonego bufora
Jak wygląda teraz przebieg i poszczególne etapy przygotowywania i wysyłania danych z bufora?
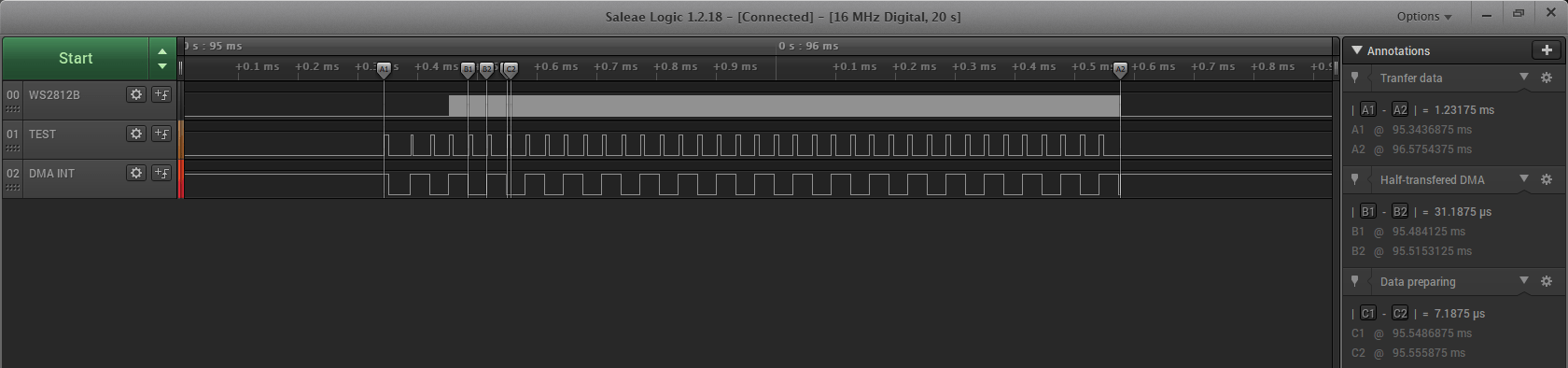
Czas transferu całej ramki nie uległ zmianie znaczącej zmianie. Całościowo transfer wzrósł nieznacznie do 1,23 ms. Czas wymagany na przesłanie połowy bufora(24 bajty) przez DMA to 31 µs. Bardzo mało. Przygotowanie kolejnej porcji 24 bajtów danych zajmuje MCU jedynie 7 µs. Daje to 26 µs oszczędności czasu na CPU dla jednej diody, który może zajmować się czymś innym. Mało? Przy 100 diodach będzie to 2,6 ms natomiast przy 1000 mamy 26 ms czasu dla CPU. Różnice czasu transferu w porównaniu do przesłania jednego, dużego bufora są niewielkie. Za to jaka oszczędność RAMu! 912 bajtów dla pełnego bufora vs 48 bajtów dla porcjowania i to tylko przy 35 diodach. Zwiększając liczbę świecących punktów w łańcuchu oraz trzymając się koncepcji z jednym, wielkim buforem wielkość bufora drastycznie rośnie. 100 diod to już ~2,4 kB danych. Natomiast korzystając z małego bufora i połówkowych przerwań DMA bufor pozostaje niezmienny! Pięknie.
Podsumowanie
Diody WS2812B są świetne. Przy na prawdę minimalnej ilości połączeń jesteśmy w stanie ustawić KAŻDĄ diodę z osobna. Co prawda nie ma tu faktycznego adresowania diod, ale w łatwy sposób można się po nich poruszać w buforze. Efekt ten uzyskujemy bez multipleksowania i bez rozdzielania kanałów dla kolorów. Sterowanie może wydawać się kłopotliwe, ale umiejętne wykorzystanie standardowych interfejsów w STM32 pozwala na bezproblemową kontrolę naprawdę długich łańcuchów. Przedstawione w tym wpisie wykorzystanie SPI ma jedną, podstawową wadę. Pin odpowiedzialny za SCK interfejsu szeregowego jest nieużywany i nie można nic z nim zrobić(bynajmniej ja o tym nic nie wiem). Tworząc upchany i skomplikowany projekt ten pin mógłby się przydać. Na szczęście większość znanych mi projektów wykorzystujących efekciarskie kombinacje na diodach nie zawiera zbyt dużo układów połączonych do MCU. Bierz i twórz swoje! Za dwa tygodnie zaprezentuję kilka gotowych efektów świetlnych, które z pewnością przydadzą się na choince.
Dziękuję Ci za przeczytanie tego wpisu. Jeśli taka tematyka Ci odpowiada, daj mi znać w komentarzu. Będę też wdzięczny za propozycję tematów które chciałbyś abym poruszył.
Kod standardowo dostępny jest na moim GitHubie: link
Jeśli zauważyłeś jakiś błąd, nie zgadzasz się z czymś, chciałbyś coś dodać istotnego lub po prostu uważasz, że chciałbyś podystkutować w tym temacie, napisz komentarz. Pamiętaj, że dyskusja ma być kulturalna i zgodna z zasadami języka polskiego.
Ten artykuł jest częścią cyklu:
Podobne artykuły







48 komentarzy
Smigl0 · 03/03/2025 o 21:33
Witam, znalazłem małego buga w związku z zaświecaniem dodatkowych diod.
powinno być tak w funkcji void HAL_SPI_TxCpltCallback(SPI_HandleTypeDef *hspi)
if(CurrentLed >= WS2812B_LEDS) a było if(CurrentLed > WS2812B_LEDS)
to samo jest w w funkcji void HAL_SPI_TxHalfCpltCallback(SPI_HandleTypeDef *hspi)
problem mam jeszcze z pierwszą diodą. Bo jak chcę nimi migać naprzemiennie 0-zielony, 1-czerwony i po jakimś czasie zmiana kolorów miejscami to migają mi obie na zielono lub czerwono równocześnie.
Krzychu1995 · 04/09/2021 o 07:12
Cześć wam!
Ostatnio na polskiej stronie znalazłem metodę z użyciem timera i PWM. Czy nie byłaby ona lepsza?
W tamtym przykładzie użyli uC z taktowaniem 80MHz, więc wystarczyło ustawić auto reload timera na 99 żeby mieć wymagane 800 kHz. Żeby wysłać bity to wystarczyło zmieniać szerokość impulsu dla każdego cyklu, za pomocą DMA tak, aby procent wypełnienia odpowiadał wartościom z datasheeta WS2812B. U siebie mam dużo szybszy STM32F407VGT o taktowaniu 168 MHz, na timery trafia bodajże 84 MHz, przez co autoreload musiałem ustawić na 104 żeby zniwelować dodatkowe herce, tak samo musiałem dostosować szerokości impulsu w programie.
Przepraszam ze nieco przydługi wywód, ale opis z tej strony o użyciu SPI trochę mnie wystraszył. PWM natomiast opanowałem w miarę sprawnie.
Marcin · 01/02/2021 o 00:33
Hej Mateusz,
Skorzystałem z Twojej biblioteki do sterowania i natrafiłem na dziwny problem.
Nie zawsze bufor jest właściwie wysyłany.
WS2812B_Init(&hspi1);
WS2812B_SetDiodeColor(1, 0xFF0000);
WS2812B_Refresh();
Ta sekwencja zapala drugą i czwartą diodę. Dlaczego czwartą również?
Sprawdziłem na analizatorze i się zgadza… wysyła również dla czwartej.
Dodatkowo mam ustawione 11 LEDów, a wysyła dla 13 i pół 🙂
Czy ktoś spotkał się z problemem?
Może ja mam coś źle ustawione? Tylko co?
Mateusz Salamon · 03/02/2021 o 13:09
Hmm… może jest jakiś mały Bug w przeliczaniu ilości diod do podesłania. W sumie też czasami zauważyłem jakieś dziwne zachowanie, gdy korzystałem z mniejszej ilości diod niż jest ogólnie na pasku… Trzeba będzie przejrzeć callbacki od DMA bo to w nich liczona jest ilość wysyłanych diod.
Marcin · 18/07/2021 o 18:48
Mam taki problem:
WS2812B_Init(&hspi1);
WS2812B_SetDiodeColor(0, 0xFF0000);
WS2812B_Refresh();
Pomimo SetDiodeColor() zawsze SPI wysyła full bufor na wszystkie biały (FFFFFF). Gdzie mogę debugować problem? Czy ktoś z Was spotkał się już z tym problemem?
Mateusz Salamon · 26/07/2021 o 18:00
Nieskonfigurowane DMA? Tak strzelam. Debuguj procedurę wysłania i zobacz czy pobiera kolory i śle je na SPI.
Grzegorz · 17/04/2021 o 15:39
Rozwiazałeś ten problem? Ja zaeksperymentowałem z rozmiarem bufora:
#define rozmiar_buffer 96
static uint8_t buffer[rozmiar_buffer];
ustawiłem na 96 i oczywiście pozmieniałem powiązane wartości w innych miejscach i o dziwo działa teraz poprawnie.
Daniel · 03/12/2020 o 05:15
Szanowni :). Ja tylko przestrzegę, żebyście dobrze sprawdzali, który model WS-2812B macie :). Mateusz wrzuca tutaj “timingi” do podstawowego modelu WS2812B – chociaż da się znaleźć też inne, np.:
https://cdn-shop.adafruit.com/datasheets/WS2812B.pdf
Czyli zamiast 0.35 mamy 0.4 albo 0.45, a zamiast 0.9 mamy 0.8 lub 0.85 (przy 0.15 maksymalnym odchyleniu – to może zrobić różnicę 😉 ).
Ale są też modele “czarne”, WS2812B-B, przy czym jest to wersja 5 (v5) – różnią się nie tylko kolorem obudowy, ale też timingami:
http://www.world-semi.com/DownLoadFile/111
Tutaj czas “niski” jedynki, T1L, jest również długi (przez co bity 1 i 0 mają różne czasy trwania), a do tego reset to >280 us (już 50 nie wystarcza).
Mateusz Salamon · 03/12/2020 o 09:02
Widzę, że ostro jedziesz z diodami na święta 🙂 W sumie to nie spodziewałem się, że będą różnice między “WSami”. Dzięki za spostrzeżenie!
Sas · 03/12/2019 o 14:24
Nie wiem dlaczego praktycznie wszystkie rozwiązania sterowania WS281x są oparte o SPI jeśli UART jest wygodniejszy w użyciu?
Wystarczy wybrać 7N1, BAUD=2.4Mb/s. W jednym bajcie zawarte są 3 bity dla WS281x więc jeden LED to 8 bajtów RAM. To zdecydowanie mniej niż w przypadku SPI – 24 bajty a przy innym podejściu 9 bajtów. Sygnał z UART należy zanegować ale tylko najstarsze STM32 nie mają takiej opcji. Przy okazji, ustawiając tryb OD, dodając na wyjściu TX rezystor podciągający do 5V mamy konwerter poziomów 3.3V na 5V.
PS
Pomijam rozwiązania z timerami,. Są o tyle ciekawe, że jeden bajt dla WS2812 to jeden bajt w RAM czyli jeden WS2812 = 3 bajty RAM. Niestety, na każdej rodzinie uC realizowane jest to w odmienny sposób a rozwiązanie z USART dział na STM32 jak i LPC, czy nawet AVR 9niestery, obciążenie CPU 80..90%).
Mateusz Salamon · 08/12/2019 o 15:09
Dzięki za wskazówkę z UART. Przyjrzę się temu na pewno. Niestety z Timerapwymi rozwiązaniami jest tak jak mówisz. Ciężko o jeden opis dla wszystkich MCU i jest trochę więcej ginmastyki.
SaS · 12/12/2019 o 20:45
Nie ma się co przyglądać. Używałem na AVR:
https://www.youtube.com/watch?v=h2RKAJZdVl4
https://www.youtube.com/watch?v=hBovo7Y0fRY
https://www.youtube.com/watch?v=aM9hy4EpleY
Niestety, jak już pisałem, obciążenie CPU w czasie transmisji 80..90% ale jak się pomęczyć, trochę wspomóc sprzętem (zewnętrzne UART ISC16IS7xx FIFO 64bajty), to można dekodować DMX po UART (ISC16IS760 odbiornik) lub po USB (FT22x – mostek USB-SPI), wysyłać dane do WS281x i UART (ISC16IS760 nadajnik). Naturalnie, jest to nieekonomiczne, taniej, lepiej i szybciej zrobić to na STM32.
Na STM32 też robiłem używając UART:
https://www.youtube.com/playlist?list=PLdtkbzWTUVMmcBIw0RFHR41xYL1VMijrd
Obciążenie CPU 1..2%. Porównywać do AVR nie ma co.
Barthap · 08/04/2020 o 00:08
Na AVR z serii Xmega jest wydajne rozwiązanie właśnie z użyciem UART + DMA
http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-2.html
http://mikrokontrolery.blogspot.com/2011/03/Diody-WS2812B-sterowanie-XMega-cz-3.html
W analogiczny sposób można to pewnie przeportować na STM32
Mateusz Salamon · 08/04/2020 o 19:30
Dzięki! Wygląda to fajnie i pewnie uda się coś zaczerpnąć 🙂
Kamil_Lwo · 30/03/2019 o 11:21
Witam Ponownie.
Mateusz, uporałem się po części z zasilaniem. Teraz mam zasilanie na początku paska w środku i na końcu. W wolnym czasie jeszcze to rozdzielę. Ogólnie jest w miarę OK. Na trzech segmentach niektóre funkcje potrafią się na siebie “nałożyć”, i zaczyna się wszystko krzaczyć. Jak ustawie jeden segment, tak jak napisałem, jest w miarę OK.
Teraz co do samych funkcji.
Na trzech segmentach funkcja Next krzaczyła się praktycznie zawsze.
Na jednym tak jak by nie przewija się do początku, po przepełnieniu. Czyli dojadę do końca efektów , i kolejne Next zawiesza działanie paska, trzeba wystartować segment od nowa.
Prev po przepełnieniu też nie działa. Ogólnie na jednym segmencie te funkcje śmigają fajnie.
No i teraz będzie pytanie ;-). Szybkość animacji.
#define SPEED_MIN 10
#define DEFAULT_SPEED 150
#define SPEED_MAX 65535
Jak ustawię speed na 10, jedna kropka przelatuje mi przez 300 diód 3sek. W tym pasku, jest to metr na sekundę , trochę wolno ;-/. Zmieniłem w kodzie na:
#define SPEED_MIN 1
Jednak to nie działa , nie ma różnicy w szybkości animacji wszystko poniżej 10. Przynajmniej u mnie ;-/.
Czy 10 to graniczny czas animacji, czy coś źle kombinuje?
I drugie pytanie. Wspominałeś o poprawkach pewnych zmiennych. Które muszę zmienić u siebie , żeby nie doszło do ich przepełnienia?
Mateusz · 30/03/2019 o 12:37
Poprawiony kod masz na Githubie. Co do prędkości to możesz zmienić i na 1. Są to milisekundy pomiędzie każdym przejściem w trybie za wyjątkiem trybów o których wspominałem w artykule. Poza tym te prędkości to tylko define’y. Dla każdego segmentu ustalasz ją osobno przez funkcje.
Kamil_Lwo · 09/03/2019 o 15:53
Witam Ponownie. Na jak długim pasku to pędziliście? Mi przy 30 diodach działa miodzio, wszystkie funkcje śmigają. Jednak przy 300 sztukach zaczyna się wszystko krzaczyć ;-/. Znaczy efekty ustawione na “starcie” odpalają, jednak próba zmiany efektu działa już losowo ;-/
Mateusz · 09/03/2019 o 15:58
Hmm. Na pierwszy rzut oka wygląda na przekraczanie jakiegoś zakresu. Jak wygląda działanie dla 255 i 256 diod?
Kamil_Lwo · 09/03/2019 o 16:30
Mateusz, jak wrócę do domu to będę robił testy. Nie mam pod ręką kodu teraz, a mam pytanie.
Żeby na razie nie bawić się w segmenty, ustawiam na początku w inicjalizacji że jeden segment. I to wszystko?
Mateusz · 09/03/2019 o 16:32
Ja za to chyba nie mam aż tylu diod, aby powalczyć 🙁 Tak, wystarczy ustalić jeden segment.
Mateusz · 09/03/2019 o 17:19
Jednak znalazłem ok 300 sztuk. Nie udało mi się wywołać jakiegoś szaleństwa. Musisz mi podać dokładniej co robisz, że nie działa poprawnie. Zaktualizowałem też delikatnie kod z podejrzeniem, gdzie może dojść do przeładowania zmiennej.
Piotr · 09/03/2019 o 17:33
A zmierz napięcie na 300 diodzie i sprawdź czy jest 5V 😉
Mateusz · 09/03/2019 o 17:36
Ooo tak, to jest ważne. Ja akurat miałem dwa łańcuchy i wpłąłem się zasilaniem pomiędzy nimi. Zasilając z jednej strony może być problemem. Przy wszystkich białych diodach będziesz miał ok 15A prądu
Kamil_Lwo · 12/03/2019 o 16:23
Witam, przepraszam że tak długo.
Podłączam zasilanie z dwóch stron, zmniejszam ilość diód do 200, czy też nawet 100.
Co chwila wpada jakaś szpila, i pasek głupieje ;-/
Czekam na drugi zasilacz , chociaż teraz jadę na serwisowym, Amper nie brakuje na pewno.
Jeszcze myślę o konwerterze poziomów logicznych. Na drugim pasku 30 diodowym, wszystko jest OK.
Mateusz · 12/03/2019 o 19:19
Sprawdź ten konwerter. Wg noty minimum dla stanu wysokiego to 0,7 * VDD, czyli 3,5 V dla zasilania z 5V. Być może masz mniej tolerancyjne diody.
Piotr · 12/03/2019 o 16:30
To teraz sprawdź jakie masz napięcie w środku (po 100-tnej diodzie );)
Piotr · 19/02/2019 o 20:14
Hej,
Na screenie okna “SPI Configuration” masz pokazane, że “First Bit” jest wybrany jako “MSB First”. Natomiast parę linijek poniżej masz napisane, że “…że SPI transferowane jest od LSB …”.
Więc jak powinno być finalnie ? 🙂
Mateusz · 19/02/2019 o 21:22
Cześć! Jak ja się cieszę, że czytają mnie mądre i uważne osoby 🙂 Oczywiście zaprzeczyłem niejako samemu sobie(nie wiem w jakim stanie to pisałem i później czytałem :P). Powinno być wszystko na MSB, również konstrukcja bitów dla jedynki i zera. Poprawiłem to w tekście oraz w kodzie na GitHubie. Oczywiście przetestowałem – działa. Dziwi mnie jedynie, że definicje były dla LSB First, a pasek mimo tego działał bez zarzutu. No cóż, może fartem mieściłem się w tolerancjach układu 🙂 Dzięki jeszcze raz za znalezienie błędu!
Piotr · 19/02/2019 o 22:41
Przerabiam (próbuje przerobić 🙂 ) Twój kod na LL i stąd wyłapałem ten bug 🙂 A jeżeli zostawisz LSB i starą definicję “#define zero” i “#define one” to nie będzie to samo ?
Mateusz · 20/02/2019 o 06:28
Jak zmienisz w Cube na LSB to będzie to samo 🙂
Kamil_Lwo · 09/02/2019 o 12:22
Witam!
Jest część pierwsza, jest trzecia, a gdzie druga? ;-). Ktoś przteransportował to pod F104?
Mateusz · 09/02/2019 o 14:32
Juz jest, dzięki za zwrócenie uwagi 🙂 Myslę, że nie będzie większych problemów z implementacją na F104. Kod starałem się pisać tak, że po odpowiedniej konfiguracji w Cube, dasz radę podciągnąć libkę pod każdy STM.
Piotr · 07/02/2019 o 21:04
Hej, świetny artykuł 🙂
Powiedz mi w jaki sposób ustawiasz CubeMXa, że masz takie drzewo w folderze Src ? 🙂
Mateusz · 07/02/2019 o 21:11
Jeśli chodzi o pojedyncze pliki jak dma.c, gpio.c itd to odpowiada za to Generate peripheral initialization as a pair of ‘.c/.h’ files per peripheral w zakładce Project Manager -> Code Generator
Piotr · 07/02/2019 o 23:24
O to mi chodziło ?
To jeszcze jedno pytanie, co należy zaznaczyć, mieć taki wygląd drzewa jaki umieściłeś na GitHubie? ?
Mateusz · 08/02/2019 o 05:50
Nie bardzo wiem o co Ci chodzi 🙂 Na githuba wrzucam cały projekt po prostu.
Michał · 26/12/2018 o 20:22
Faktycznie nie przeczytałem tego ze zrozumieniem 🙂 Starałem się przejść ten temat krok po kroku tak jak opisujesz 😉 i po wygenerowaniu konfiguracji w cube już nie zaprzątałem sobie nią głowy 🙂 Ale działa i to bardzo fajnie 🙂 Kawał dobrej roboty!
Ja swój program kompilowałem w keilu. Mysiałem kilka rzeczy pozmieniać, żeby nie sypał błędami:
1. Nie wiem czego ale nie ogarniał takiego zapisu bitowego, więc zamieniłem na bajty (ws2821b.c)
//#define zero 0b00000011
//#define one 0b00011111
#define zero 0x03
#define one 0x1F
2. W pliku ws2812b_fx.c
Wszystkie funkcje typu void z parametrem return np.
void mode_twinkle_random(void)
{
// return
twinkle(color_wheel(rand() % 256), Ws28b12b_Segments[mActualSegment].ModeColor[1]);
}
Keil sie obraził za używanie return przy uruchomieniu funkcji, które nic nie zwracają. Więc zakomentowałem tj. wyżej;)
3.Brakujące includy:
W pliku ws2812b.h:
#include – w sumie to nie wiem dlaczego nie rozpoznawał typów zmiennych w plikach zewnętrznych
W pliku ws2812b_fx.h:
#include “ws2812b.h”
#include
Mateusz · 26/12/2018 o 20:28
Świetnie, że się udało. Z Keila prawie w ogóle nie korzystam 🙁 Pewnie masz trochę inne parametry kompilacji, bardziej restrykcyjne i nie przepuszcza takich akcji
Grunt, że dałeś radę.
Michał · 26/12/2018 o 20:30
Chyba użyłem jakiś specjalnych znaków bo zjadło część tekstu #include “stdint.h” oczywiście w klamerkach ostrych a nie w cudzysłowach
Michał · 26/12/2018 o 16:36
No powiem Ci sporo się namęczyłem z Twoim kodem zanim zaczął mi działać. Zastanawia mnie tylko jedno dlaczego umieściłeś czyszczenie bufora dla SPI przed jego wysłaniem ?
To celowe zagranie ?:)
Mateusz · 26/12/2018 o 17:29
Chodzi Ci o te 48 bajtów w funkcji Refresh? To jest na potrzeby resetu. Na czym uruchamiałeś? F103 tak jak ja?
Michał · 26/12/2018 o 18:04
Tak dokładnie. Bez zakomentowania tych 48 bajtów na oscyloskopie widzę, że nic po SPI nie leci. Szukałem też w kodzie czy gdzieś w innym miejscu nie wrzucasz coś do bufora DMA do wysłania po SPI ale jedyne co znalazłem to tą funkcje refresh. Tak Dokładnie na F103
Mateusz · 26/12/2018 o 18:06
W przerwaniach od DMA ciąglę aktualizuję ten bufor. Ciekawe, że zakomentowanie tego powoduje nieruszanie transmisji.
Mateusz · 26/12/2018 o 18:14
A może za dużo komentujesz? ?
Michał · 26/12/2018 o 19:22
Chyba znalazłem gdzie był błąd! W tekście powyżej opisujesz, że DMA musi być w trybie NORMAL. Po przestawieniu w tryb CIRCULAR wszystko działa tak jak trzeba 🙂
Mateusz · 26/12/2018 o 19:34
Aaa to chyba nie doczytałeś wpisu do końca ? Początkowo zrobiłem to na jednym, sporym buforze, ale cały kod ewoluował na cykliczne DMA, ale faktycznie powinienem to napisać jaśniej i bardziej wprost ? Dobrze, że się ostatecznie udało.
Konari · 02/11/2018 o 21:05
Czy próbowałeś generować przebiegi przez GPIO ? Czy od razu założyłeś że zrobisz przez SPI ?
Mateusz · 02/11/2018 o 22:09
Cześć! Od razu założyłem, że użyję SPI. Chcę spróbować jeszcze generować sygnał przy pomocy Timera, ale czy to będzie GPIO to nie mogę obiecać. Na pewno da się to pożenić z PWM i DMA i efekt będzie podobny to tego na SPI z tym, że będzie do wyboru któryś z kanałów PWM Timera. Na pewno napiszę o tym, czy mi się udało czy nie. Jak się uda to będzie opisane całe rozwiązanie wraz z kodem 🙂