Podczas dalszego rozwijania biblioteki do układu nRF24L01+ postanowiłem skorzystać z buforów kołowych. Stwierdziłem zatem, że jest to dobry moment, aby Cię najpierw wprowadzić w ich temat jeszcze zanim pokażę, w jaki sposób zaimplementowałem je do komunikacji radiowej. Czy jest ta struktura do przechowywania danych i jak się z nią obchodzić?

Bufor kołowy
Nazywają je różnie: kołowy, cykliczny, pierścieniowy. Wszystkie te nazwy na ogół prowadzą to tego samego. Czym to właściwie jest i dlaczego nie używać po prostu zwykłej tablicy?
No właśnie. Można przecież wrzucać dane do tablicy i czytać tę tablicę. Rozwiązanie najprostsze i pewnie w wielu miejscach wystarczające. Problem przychodzi, kiedy zadamy sobie kilka pytań:
- W które miejsce w tablicy wrzucić nową daną lub odczytać?
- Ile elementów mogę jeszcze wpisać do tablicy?
- Czy aktualna pozycja to aktualne zapełnienie?
- Czy jak odczytałem bajt z pozycji zerowej to kolejną nową daną wpisać tam, czy na koniec?
- Czy dane, które są w tablicy były już odczytane/użyte?
- Co, jeśli zapełnię tablicę? Muszę pamiętać o tym jaki ma rozmiar, aby nie wyjechać poza zakres.
Tych pytań może być dużo więcej. Tablice są spoko do rzeczy chwilowych jak np. bufor, który pchamy za chwilę na UART. Wtedy zawsze korzystam z tablicy w sposób jednorazowy.
Bufor kołowy przyda nam się, jeśli chcemy, aby nasze dane żyły dłużej i na przestrzeni większego fragmentu programu. Poza tym wprowadzają porządek, bo takie rzeczy jak ilość danych nieobrobionych czy przepełnienie pilnowane są z automatu.
Przykładowo przy komunikacji z nRF24 dane, które przychodzą w “losowym” momencie przez przerwanie trafiają do bufora odbiorczego i nie chcemy tymi danymi zajmować się w procedurze obsługi przerwania. Możemy na przykład zająć się nimi po nadejściu jakiegoś konkretnego znaku. Obrobimy je dopiero wtedy, gdy będzie na nie odpowiedni czas. Zanim się nimi zajmiemy mogą przyjść kolejne dane. Trzeba je wszystkie gdzieś przechować.
Teraz drugą stronę. Chcemy coś nadać przez nRF24. Możemy wpisać po prostu do układu to, co chcemy wysłać i on to pośle. Co, jeśli mamy do wysłania więcej danych niż układ może nadać na raz? Czekać bezczynnie na nadanie pierwszej paczki? Oczywiście nie lubimy takiego oczekiwania 🙂
Możesz wpisać do bufora kołowego 100 bajtów i wysyłać je porcjami w momentach, kiedy jest na to czas i układ nadawczy jest wolny. Procedura wysyłki powinna sama pobierać dane z bufora bez angażowania nas.
Działanie bufora kołowego
Bufor kołowy jest w sumie kolejką FIFO (First In First Out). Oznacza to tyle, że dana, którą wpiszesz do bufora jest pobierana z niego jako pierwsza. FIFOki to jedne z najpopularniejszych form buforowania.
Dlaczego więc kołowy czy tam cykliczny? Wszystko dlatego, że teoretyczne ułożenie danych przypomina okrąg 🙂 Dobrze to wizualizuje obrazek z Wikipedii:
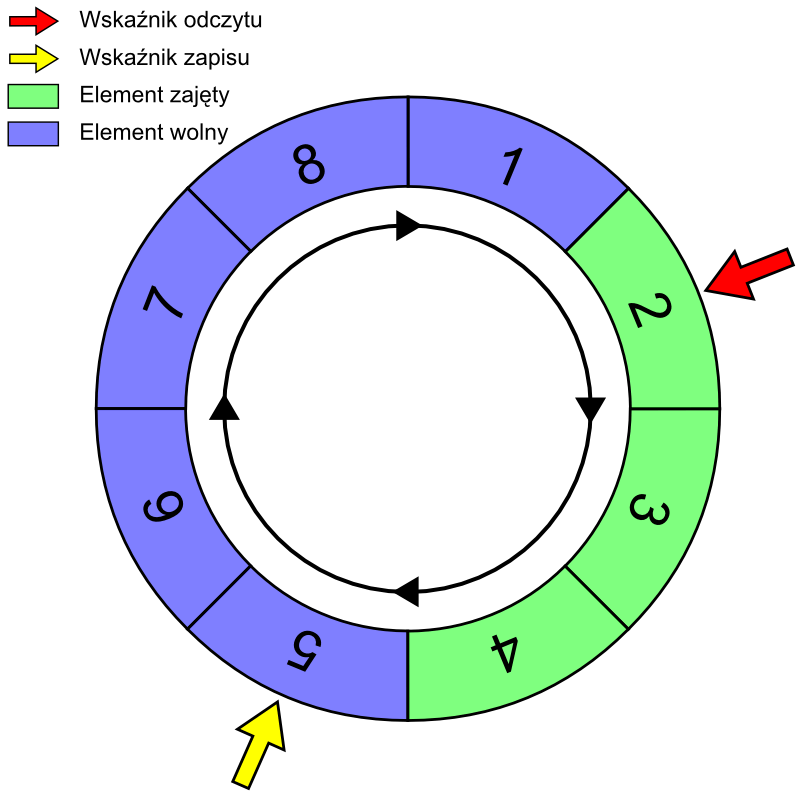
Na obrazku masz bufor cykliczny o rozmiarze 8 bajtów. Zobacz na tę żółtą strzałkę, która jest wskaźnikiem kolejnego zapisu. Kiedy dojdzie do bajtu nr 8, kolejnym miejscem, w które będzie do wpisania w buforze będzie bajt nr 1. Podobnie z odczytem. Przejście przez bajt ósmy spowoduje, że kolejnym do odczytu będzie pierwszy bajt. Stąd właśnie wzięła się kołowa interpretacja tej struktury danych jako przestrzeń kołowa.
Jak zrobić cykliczną strukturę w pamięci?
Niestety tej cykliczności w teorii nie można przełożyć wprost na pamięć w mikrokontrolerze. Pamięć RAM w uC jest ciągła i o wiele większa niż nasz bufor. On z kolei znajduje się gdzieś po środu pamięci. Załóżmy, że mamy ten bufor 8-bajtowy o adresach 0x10÷0x17. Jeśli wskaźnik zapisu będzie na adresie 0x17, to wpisanie tam bajtu i inkrementacja nie “cofnie” nas automatycznie do 0x10. Normalnie wskaźnik ten wyląduje a 0x18, czyli wyjdzie poza tablicę. To jest właśnie to, czego nie chcemy.
Trzeba pomóc wskaźnikowi wrócić na miejsce zerowe. Jak to zrobić? Sprawdzić po inkrementacji wskaźnika czy nie wyszedł poza zakres. Można to zrobić na dwa sposoby:
- Przy pomocy if(WritePointer > BufferSize-1) { WritePointer = 0};
- Wykonać po prostu dzielenie modulo na wskaźniku: WritePointer %= BufferSize;
Ja wybieram zawsze ten drugi wariant. Dzielenie modulo przez rozmiar bufora nigdy nie pozwoli na wyjście poza zakres rozmiaru tablicy.
Elementy pomocnicze bufora
Już pewnie zauważyłeś, że potrzebujemy coś więcej niż samą tablicę, do której będziemy pisać. Potrzebne są wskaźniki zapisu i odczytu. Do czego one są?
Chcemy, aby pisanie i czytanie z bufora nie było uzależnione od podania numeru komórki, której chcemy użyć. Ma się to dziać w tle z dala od użytkownika. Struktura więc musi sama pamiętać, w którą komórkę trzeba będzie wpisać kolejny bajt, a z której odczytać.
Te wskaźniki to Head oraz Tail. Nazewnictwo wzięte jest najprawdopodobniej z węża. Głowa węża to miejsce, gdzie będą wpisywane kolejne dane, ogon wskazuje na pierwsze do odczytu bajt.
Grałeś pewnie w Snake’a na Nokii, co? Pamiętasz co oznacza sytuacja, gdy głowa dogoni ogon? Game Over. Podobnie jest tutaj. Jeśli dogonimy głową ogon, oznaczać to będzie, że nie ma już miejsca w buforze.
Z drugiej strony taki Game Over osiągniesz przy próbie odczytu pustego bufora, czyli gdy ogon dogoni głowę.
Te dwie sytuacje krańcowe możesz wykryć i w jakiś sposób obsłużyć. Częściej będziesz miał do czynienia z pustym buforem – w końcu dążymy do tego, aby obrobić wszystkie dane w nim zawarte. Wtedy warto sygnalizować, że nie ma co czytać.
Jak więc w tym momencie będzie wyglądał nasz bufor? Będzie to struktura z tablicą oraz dwoma “wskaźnikami” adresującymi tę tablicę. Jest to najprostsza forma bufora.
#define BUFFER_SIZE 32
typedef struct
{
uint8_t Buffer[BUFFER_SIZE];
uint8_t Head;
uint8_t Tail;
} RingBuffer;
Zapis do bufora
Z punktu widzenia użycia bufora potrzebujemy tak naprawdę dwóch funkcji: zapisania i odczytania bajtu z bufora. Wezmę najpierw zapis.
Świeżo utworzona struktura ma na swoich polach same zera, więc wskaźniki Head i Tail wskazują na pierwszą komórkę tablicy bufora. Aby wpisać coś do bufora musisz:
- Upewnić się, że jest miejsce
- Wpisać daną w kolejne wolne miejsce
- Zinkrementować wskaźnik zapisu pamiętając o “cykliczności”
I to tyle! Jak się upewnić, że mamy miejsce do wpisania? Jest kilka sposobów łącznie z dodaniem dodatkowego pola w strukturze zliczającą liczbę elementów w buforze, co jest całkiem niezłym rozwiązaniem.
Jednak najprostszą metodą będzie sprawdzenie, czy następny w kolejności wskaźnik zapisu (głowa) nie “uderzy” w ogon węża.
int8_t WriteToBuffer(RingBuffer *Buffer, uint8_t Data)
{
uint8_t TempHead;
TempHead = (Buffer->Head + 1) % BUFFER_SIZE;
if( TempHead == Buffer->Tail) // No room for new data
{
return -1;
}
else
{
// Write to buffer
}
return 0;
}
Pomaga mi w tym dodatkowa zmienna pomocnicza TempHead, w której trzymam obliczoną kolejną pozycję głowy. Można się tez obyć bez niej, ale tak będzie czytelniej. Następnie porównuję ją z aktualnym ogonem i gdy są równe zwracam błąd -1. Jeśli będą różne to oznacza, że jest miejsce i można pisać.
Punkt pierwszy z listy jest spełnony. Jak wygląda drugi i trzeci punkt, czyli zapis i inkrementacja?
Buffer->Buffer[Buffer->Head] = Data; Buffer->Head++; Buffer->Head %= BUFFER_SIZE;
Wiedzą, że jest miejsce mogę spokojnie zapisać bajt i zinkrementować wskaźnik zapisu do kolejnej “wolnej” komórki
Cała funkcja wygląda więc tak
int8_t WriteToBuffer(RingBuffer *Buffer, uint8_t Data)
{
uint8_t TempHead;
TempHead = (Buffer->Head + 1) % BUFFER_SIZE;
if( TempHead == Buffer->Tail) // No room for new data
{
return -1;
}
else
{
Buffer->Buffer[Buffer->Head] = Data;
Buffer->Head++;
Buffer->Head %= BUFFER_SIZE;
}
return 0;
}
Odczyt z bufora
Teraz wypadałoby odczytać bajt, który już jest wpisany do bufora. Odczyt jest analogiczny do zapisu przy czym nie sprawdzam czy jest miejsce w kolejnej komórce, tylko patrzę czy Tail nie zrównał się już z Head. Jeśli tak, to nie ma co czytać.
int8_t ReadFromBuffer(RingBuffer *Buffer, uint8_t *Data)
{
if( Buffer->Tail == Buffer->Head) // No data to read
{
return -1;
}
else
{
*Data = Buffer->Buffer[Buffer->Tail];
Buffer->Tail++;
Buffer->Tail %= BUFFER_SIZE;
Buffer->Elements--;
}
return 0;
}
Ile bajtów mieści się w takim buforze?
Może wydawać się to proste i oczywiste, że skoro mam tablicę 32 bajtową, to zmieszczę tak 32 bajty.
Otóż nie. W takiej tablicy przechować mogę 31 bajtów. Zauważ, że przy pisaniu, jeśli przed wskaźnikiem zapisu nie ma wolnego miejsca, to nie wpiszę nic w aktualne miejsce. Stąd zawsze jeden bajt musi być “wolny”.
Dlaczego tak zrobiłem? Wystarczy zadać proste pytanie: Czy jak Head i Tail są równe to bufor jest pełny czy pusty? Tutaj tkwi wbrew pozorom solidny problem, którego bez dodatkowych wskaźników nie da się rozwiązać. Rozwiązania są co najmniej trzy, a przynajmniej tyle na ten moment znam:
- Wykorzystanie jednego bajtu “wolnego” w tablicy jako wskaźnik pusty/pełny. Tak zrobiłem w tutejszych przykładach.
- Zliczanie elementów przy zapisie i odliczanie ich przy odczycie w dodatkowym polu struktury. Skuteczne, dopóki nie używamy intensywnie bufora z przerwaniami czy RTOS. Wtedy potrzebne są dodatkowe metody synchronizacji. Bonus: w łatwy sposób wiemy ile jest dostępnych danych w buforze zanim zaczniemy je czytać.
- Połączenie dwóch powyższych metod. To docelowo użyłem przy nRF24 ze względu na bonus.
Dodatkowe funkcje buforów kołowych
Można dorzucić wiele ciekawych funkcji pomocniczych w zależności od zastosowania. Mogą to być takie rzeczy jak:
Zwracanie ilości elementów w buforze / wolnych miejsc. Przydatne w momencie czytania całości bufora.
Flush, czyli czyszczenie bufora. Zerowanie Head i Tail w momencie błędu. Na przykład, gdy rozjedzie się licznik elementów z rzeczywistym stanem bufora(na podstawie wskaźników) lub przy przepełnieniach.
Dynamiczny rozmiar bufora. Chodzi mi dokładnie o wygenerowanie kilku buforów o różnych długościach, a nie dynamiczne dokładanie i ściąganie elementów.
Jeśli znasz jeszcze jakieś ciekawe funkcje, daj znać w komentarzu.
Podsumowanie
Bufor cykliczny jest jedną z fajniejszych metod buforowania danych. Bardzo często można wykorzystać tę metodę do zbierania damych z czujników. Zbierasz w przerwaniu, a na przykład po zebraniu 100 próbek, czytasz wszystkie i je obrabiasz w innym miejscu w programie.
Zachęcam Cię do kombinowania i udoskonalania bufora. Równiez dopisywanie czy odejmowanie funkcji w zalezności od potrzeb projektu jest spoko. Ja tam zazwyczaj robię 🙂
Tym razem nie wrzucam kodu. Bufor nieco bardziej rozbudowany niż tutaj w akrtykule będzie w trzeciej części o nRF24 już niedługo.

Jeśli zauważyłeś jakiś błąd, nie zgadzasz się z czymś, chciałbyś coś dodać istotnego lub po prostu uważasz, że chciałbyś podyskutować na ten temat, napisz komentarz. Pamiętaj, że dyskusja ma być kulturalna i zgodna z zasadami języka polskiego.
Podobne artykuły







13 komentarzy
Michał · 05/03/2024 o 20:06
Cześć! Zaczynam dopiero przygodę z buforami, strukturami i UARTEM. Mam pewne pytanie co do opisanych tutaj funkcji. W funkcji odczytu jest inkrementowana zmienna “Elements”. Dobrze rozumiem, że powinna być zdefiniowana w strukturze oraz moment odczytu z rejestru do bufora powinien znajdować się zaraz przed jej inkrementacją? Z góry dziękuję za odpowiedź 🙂
Kamol · 26/06/2020 o 17:39
Cześć,
Bardzo fajny artykuł. Mam jedną wątpliwość. W funkcji WriteToBuffer w warunku else jest:
Buffer->Buffer[Buffer->Head] = Data;
Buffer->Head++;
Buffer->Head %= BUFFER_SIZE;
nie powinno być tak ?
Buffer->Head++;
Buffer->Head %= BUFFER_SIZE;
Buffer->Buffer[Buffer->Head] = Data;
Albo przynajmniej ?
Buffer->Head = TempHead;
Buffer->Buffer[Buffer->Head] = Data;
Tak, jak już ktoś wyżej napisał ?
Bo teraz jest tak, że sprawdzamy, czy jedna komórka jest wolna, a zapisujemy daną pod zupełnie inną komórkę ?
Mateusz Salamon · 26/06/2020 o 17:50
Wszystko rozbija się o to jak sprawdzasz czy jest miejsce w buforze. Tutaj poświęciłem jeden bajt bufora na to, aby był zawsze pusty. Jak nie ma wolnego przed aktualnym miejscem zapisu to znaczy, że bufor jest pełny 🙂
SaS · 19/06/2020 o 10:53
Bufory używane są najczęściej przy odbiorze dany na przerwaniach nie można więc zapomieć o kwalifikatorze volatile.
Mateusz Salamon · 19/06/2020 o 12:07
Tak jest! Wtedy volatile obowiązkowo 🙂 Ja przy nRNach akurat użyję ich “w mainie” 🙂
slawe · 18/06/2020 o 13:17
Możesz mi wytłumaczyć co Rafal ma na myśli? O co chodzi z tym “Buffer->Head = TempHead ?” ?
Mateusz Salamon · 18/06/2020 o 15:22
CHodzi o to, aby przypisać to, co wcześniej się już wyliczyło zamiast jeszcze raz liczyć 🙂
dambo · 15/06/2020 o 22:18
kompromisowym wyjściem między modulo a maską bitową jest zwykła inkrementacja, porównanie i ewentualne wyzerowanie 😛
Mateusz Salamon · 15/06/2020 o 22:21
Albo i tak 😀 Najlepiej porównać jaki asembler z tego wszystkiego wyjdzie 🙂
Rafal · 12/06/2020 o 00:25
A nie lepiej zamiast dwóch linijek
Buffer->Head++;
Buffer->Head %= BUFFER_SIZE;
w funkcji write to napisać Buffer->Head = TempHead ?
Jak pisanie jest np z kontekstu funkcji main a czytanie z przerwania ( tak jak wyrzucanie znaków na uart np ) to mamy dwie nieatomowe linijki i chyba nie zadziała to za dobrze. Porównania head i tail będą niespójne
Mateusz Salamon · 15/06/2020 o 09:59
Masz rację – można, a nawet będzie to lepsze 🙂 Dzięki za czujność!
Jacek · 11/06/2020 o 15:42
Fajny wstępniak. Generalnie nie lepiej dać constraint na size, aby były potęgami dwójki i robić & zamiast %? Ok, to pewnie szczegół, ale jakoś bardzo nie lubię % i / na uC. 😉
Mateusz Salamon · 11/06/2020 o 16:03
Taki zabieg miał ogromny sens na AVR, gdzie nie było instrukcji dzielenia i programowo zajmowało to setki czy tysiące cykli CPU. Sam tak robiłem 😀 W STMie dzielenie jest sprzętowe i w takim Cortex-M4 trwa to tylko 2-12 cykli. Dodając do tego megaherce, zysk czasowy na wymuszaniu wielkości bufora jako wielokrotność dwójki nie jest już taki wielki 🙂
Dla MCU bez sprzętowego jak najbardziej bufor wielkości 2^n i iloczyn bitowy z maską zamiast dzielenia 🙂